2025년 7월 4주차 - AI Data News Lab 2025년 7월 4주차 AI Data News Lab |
|
|
|
세상 바삭한 유리 과일 ASMR, AI라고?🤷🏻 |
|
|
요즘 틱톡, 유튜브 등 다양한 소셜 미디어에서 숏폼, 롱폼 관계없이 인기를 끌고 있는 ASMR(Autonomous Sensory Meridian Response) 콘텐츠가 있습니다. 주인공은 바로 유리 과일이나 음식을 칼로 자르는 영상인데요. 유리로 만들어진 과일이 무엇인지 잘 모르시겠다면 아래의 유튜브 영상을 재생해 보세요. 어떤 느낌인지 이해가 빠르실 겁니다. |
|
|
출처: [Whisper Nest] 1 Hour of Satisfying AI ASMR Glass Cutting Video | AI ASMR |
|
|
진짜인지 가짜인지 헷갈릴 정도로 정교한 이 영상은 AI가 만든 ASMR 영상입니다. 구글의 생성형 AI 모델인 Veo3를 활용해 만들어진 것으로, 텍스트 몇 줄만으로 초현실적인 영상을 빠르게 만들어 낼 수 있죠. 이러한 흐름을 타고 AI가 만든 기상천외한 ASMR이나 먹방 콘텐츠가 엄청나게 생산되고 있는데요.
특히, AI 먹방 콘텐츠의 경우 인간 크리에이터들이 AI를 역으로 따라 하는 영상도 유행하고 있습니다. 인간이 만드는 AI식 용암 먹방 영상은 대강 이렇습니다. 먼저 바닥에 밝은 조명판을 깔고, 투명한 그릇을 위에 올려 물엿을 부은 다음 붉은색 색소를 풉니다. 그 위로 마시멜로를 올리고 토치로 화산 표면과 유사하게 겉면을 구우면 완성입니다.
이처럼 AI가 만든 초현실적인 영상을 인간이 따라 하는 현상까지 생겨남에 따라 가상과 현실을 구분하기 위한 기준이나 제도의 필요성이 더욱 대두되고 있습니다. 한편, 인스타그램에는 해시태그로 #veo3를 단 게시물이 약 30만 개에 달하는 등 새로운 트렌드로서 입지를 넓혀 나가고 있습니다.
|
|
|
세일즈에서 AI 자동화에 있어 좋은 소식은, 효율성과 인간적인 요소 중 어느 하나만 선택할 필요는 없다는 것입니다. 올바른 도구와 AI 기반 솔루션을 활용하면 워크플로우를 간소화하고 마찰을 줄이며, 세일즈 팀이 잘할 수 있는 핵심 업무, 즉, 의미 있는 고객 관계를 구축하고 성과를 만들어내는 일에 더 집중할 수 있게 됩니다.
전통적인 AI 어시스턴트나 도구는 사용자가 시키는 일을 기다리기만 했지만, '에이전트 AI'는 훨씬 더 능동적인 파트너처럼 작동합니다. 에이전트 AI는 단순히 명령에 반응하는 수준을 넘어, 사용자의 목표를 이해하고 다양한 도구들을 조율하며 더 빠르고 스마트하게 거래를 진행할 수 있도록 도와줍니다.
에이전트형 AI는 전략적 협업자와 같습니다. “통화 일정 잡아줘”라고 말해야만 반응하는 디지털 어시스턴트가 아닌 거죠. 고객 데이터를 파악하고, 파이프라인을 이해하며, 잠재 고객에 대한 통찰을 바탕으로 항상 한발 앞서 나갈 수 있도록 도와주기도 하고요. 복잡한 수작업이나 끊임없는 사용자 입력 없이도 가능합니다.
잠재 고객의 우선순위를 정하고, 더 빠르게 응대하며, 전략을 실시간으로 최적화하도록 돕는 솔루션은 더 이상 미래의 이야기가 아닙니다. 이는 이미 현실에서 에이전틱 AI에 의해 구현되고 있는 중입니다. 기술적인 배경이 없는 사람들도 이제는 쉽게 AI 에이전트를 만들고, 조직의 필요에 맞게 커스터마이징하며, 빠르게 배포할 수 있습니다. 코드를 한 줄도 작성하지 않아도 되고, 데이터 사이언스 팀에 의존할 필요도 없습니다.
이미 많은 도구들이 나와 있는데, 핵심은 그것들을 어떻게 함께 작동하게 만들 것이냐입니다. 많은 비즈니스 리더들이 직면한 진짜 도전은 '어떤 기술을 선택할 것인가'가 아닙니다. 오히려, 선택한 기술로 인해 기존의 기술 스택에 갇히거나, 지금까지 투자한 도구들을 포기해야만 하는 상황이 더 큰 문제입니다. 특히 세일즈처럼 모든 단계가 서로 다른 방식으로 진행되는 분야에서는 한층 더 복잡합니다. 팀들은 서로 연결되지 않는 여러 도구들과 시스템을 동시에 사용하는 경우가 많은데, 이는 업무를 느리게 만들고, 명확하고 실행 가능한 인사이트를 얻기 어렵게 만듭니다.
Agentic AI가 세일즈에서 할 수 있는 일은 무엇일까요?
만약 당신이 세일즈 분야에 있다면, 아래 사례들이 생소하지 않을 겁니다. 하지만 에이전틱 AI는 이 모든 것들을 완전히 새로운 방식으로 변화시키고 있습니다.
1. 잠재 고객 탐색 및 우선순위 지정
AI 에이전트는 CRM, 이메일, 시장 데이터를 활용해 가장 가능성 높은 리드를 찾아냅니다. 구매 신호, 행동 데이터 및 적합도에 따라 우선순위를 지정해, 더 이상 가능성 없는 리드를 쫓느라 시간 낭비할 필요가 없습니다.
2. 세일즈 준비 및 지원
회의에 들어가기 전, AI 에이전트가 이미 최신 업계 인사이트, 맞춤형 피치 자료, 그리고 해당 고객을 위한 사례 연구 자료를 모두 준비해놓는다고 상상해 보세요. 이것이 바로 에이전틱 AI입니다.
3. CRM 관리 및 고객 커뮤니케이션
야근하며 데이터를 수기로 입력할 필요가 없습니다. 에이전틱 AI는 실시간으로 CRM을 업데이트하고, 통화 내용을 요약하며, 대화 패턴을 분석해 리스크나 새로운 기회를 자동으로 식별합니다.
이 모든 기능들이 어떻게 연결되며, 세일즈 팀에 어떤 가치를 제공할까요? 상상해보세요. 한 세일즈 리더가 중요한 전략 고객을 리뷰하며, 해당 고객에 맞춘 제품 교육용 자료를 생성하려고 합니다. 이때 필요한 정보를 일일이 찾아다닐 필요 없이, 그냥 이렇게 말하면 끝입니다. “Sun Corp에 대해 Product X의 세일즈 자료 만들어줘.” 한 문장이면 충분합니다. 그 뒤에서는 다음과 같은 일이 벌어집니다.
한 에이전트는 CRM 데이터를 조회해 Sun Corp가 언제 고객이 되었는지, 어떤 제품을 채택했는지, 현재 어떤 단계에 있는지를 파악합니다. 또 다른 에이전트는 관련 사례 연구, 사용 데이터, 온보딩 마일스톤 등을 찾아냅니다. 세 번째 에이전트는 Sun Corp의 산업, 단계, 목표에 맞게 커스터마이즈된 교육 자료를 작성합니다. 동시에 고객의 관심을 유지할 수 있도록, 어조와 언어 톤이 맞춰진 이메일 시퀀스도 함께 생성됩니다.
결과적으로, 전 과정이 고도로 맞춤화된 세일즈 패키지로 완성되기 때문에 곧바로 이메일 전송을 할 수 있게 되는 건데요. 별도의 수작업이나 여러 도구를 오가며 작업할 필요도 없습니다. 단 하나의 지시만으로, 시스템 전반에 걸친 지능적 조율이 이루어지는 것이죠. 이것이 바로 ‘에이전틱 AI’의 진정한 힘이라고 볼 수 있습니다. 사용자의 목표를 이해하고, 적절한 데이터를 가져오며, 복잡한 워크플로우를 실행함으로써, 팀이 가장 중요한 일, 관계 구축과 성과 창출에 집중하게 만드는 겁니다.
|
|
|
대규모 언어 모델(LLM)과 환각(Hallucination)
2022년 말 ChatGPT 웹사이트가 조용히 등장하였습니다. 특별한 홍보나 마케팅 없이 출시되었지만, 사용해 본 사람들이 소셜 미디어에 후기를 올리기 시작하면서 입소문이 빠르게 퍼졌고, 출시 5일 만에 사용자 100만 명을 돌파하였습니다. 이는 100만 명의 사용자를 확보하는데 넷플릭스가 3.5년, 페이스북이 10개월, 인스타그램이 2.5개월이 걸렸던 것과 비교하면 ChatGPT의 파급력이 얼마나 컸는지 알 수 있습니다.
그동안 대규모 언어 모델은 주로 기업이나 연구소 등에서 개발하면서 발전해 오고 있었지만 일반 대중들이 사용해 볼 수 있는 기회는 거의 없었습니다. ChatGPT는 이름에서 알 수 있듯 ‘Chat’과 ‘GPT’가 결합된 형태로 누구나 대규모 언어 모델을 대화하듯이 사용할 수 있게 하였습니다. AI인지 여부를 판별하는 대표적인 방법으로 튜링 테스트(Turing Test)1)가 있는데 ChatGPT는 튜링 테스트가 무의미하게 느껴질 정도로 어떤 질문을 하든 답변을 해주었습니다.
처음 ChatGPT가 주었던 충격과는 달리, 종종 그 답변에 고개를 갸웃거리게 되는 경우도 있었습니다. 그 이유는 바로 어떤 질문을 하든 일단 답변을 해주는 ChatGPT의 특성 때문입니다. 대표적인 사례가 ‘세종대왕 맥북 프로 던짐 사건’으로 한동안 ChatGPT를 주제로 한 밈(Meme)으로 온라인 커뮤니티에서 회자되기도 하였습니다.
|
|
|
< 그림 1. 세종대왕 맥북프로 던짐 사건에 대한 ChatGPT의 대답 > |
|
|
왜 환각이 발생할까?
우리는 세종대왕은 조선의 왕이고 맥북 프로는 현대에 출시된 제품이기 때문에 서로 시대적으로 맞지 않아 이러한 일이 일어날 수 없다는 것을 알고 있습니다. 그리고 존재할 수 없는 일이기 때문에 누군가가 우연히 똑같은 주제로 글을 썼고, 역시 우연히 ChatGPT가 해당 게시글을 크롤링해 학습하지 않은 이상, 이러한 내용이 ChatGPT의 학습 데이터에 포함되어 있었을 가능성은 매우 낮습니다.
따라서, 우리는 이 내용이 학습 데이터에 없었을 것이라고 99.99% 확신할 수 있습니다. 그렇다면 ChatGPT는 왜 이런 답변을 하였을까요? 그 이유는 ChatGPT가 트랜스포머(Transformer) 구조에서 디코더(Decoder)만 사용하는 방식으로 설계된 모델로 만들어졌기 때문입니다. |
|
|
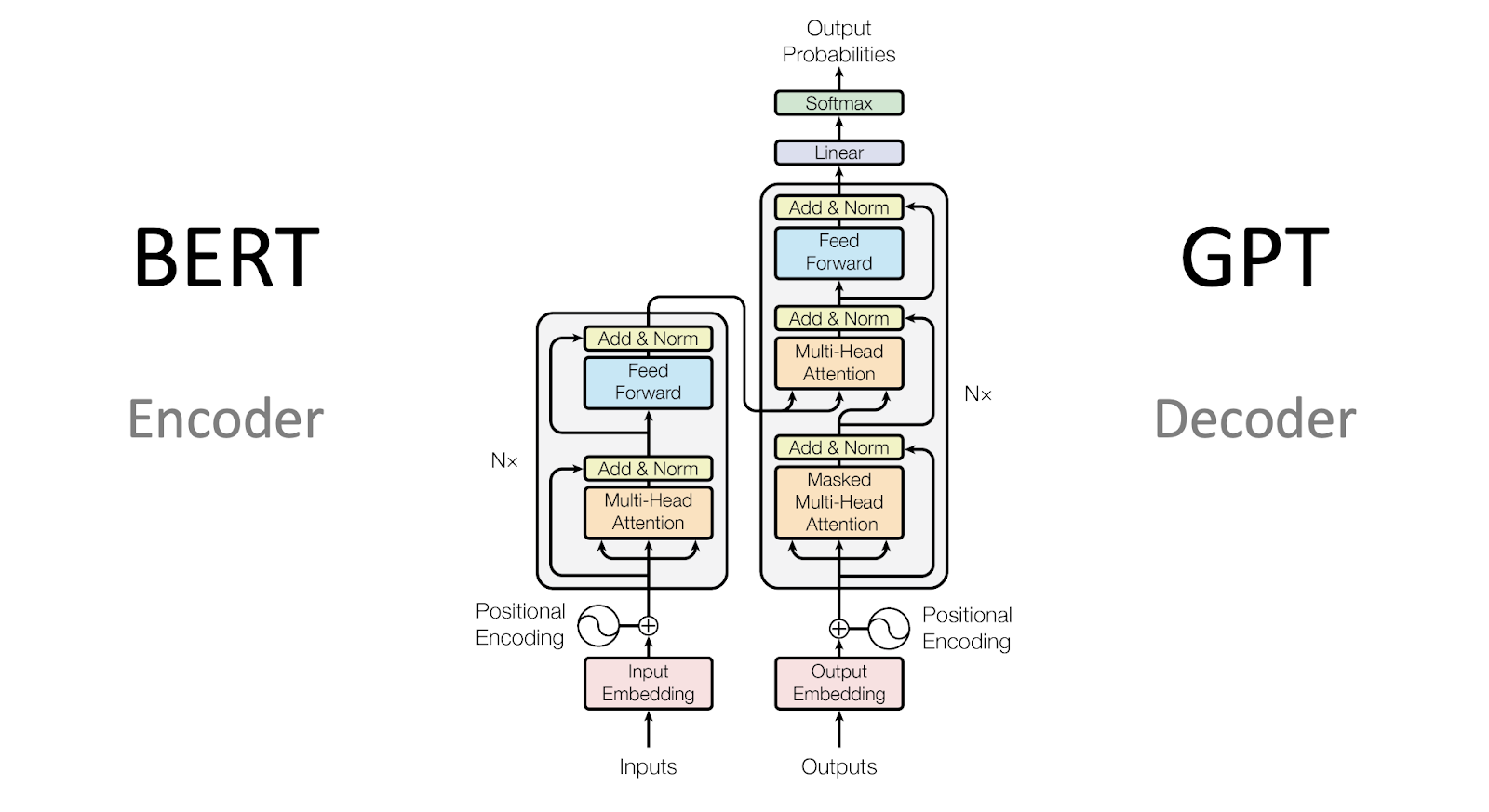
< 그림 2. Encoder-only 모델인 BERT와 Decoder-only 모델인 GPT > |
|
|
디코더 전용 모델은 인코더(Encoder)-디코더(Decoder)를 모두 사용하는 모델보다 구조가 간단합니다. 특히 디코더만 있는 모델은 자연어 생성(채팅, 요약, 문서 작성 등)에서 뛰어난 성능을 보인다고 알려져 있습니다. 디코더만으로 구성된 모델은 앞에 나오는 단어를 기반으로 다음에 나올 단어를 확률적으로 예측합니다.
만약 사람이 한 질문과 유사한 내용이 학습 데이터에 포함되어 있다면, LLM은 비교적 정확한 답을 할 가능성이 높지만, 그렇지 않은 경우 확률이 낮은 단어들 중 하나의 단어를 선택할 수밖에 없기 때문에 최종적으로 생성된 답변은 어색하거나 말이 되지 않을 수도 있습니다. 이러한 답변을 ‘환각(Hallucination)’이라고 합니다.
환각은 LLM의 구조상 숙명과도 같은 존재로 환각이 발생하지 않는 모델은 없습니다. 그렇기 때문에 LLM을 개발할 때 환각을 최소화할 수 있는 방향으로 발전해 나가고 있습니다. 추론 데이터셋(CoT - Chain of Thought)으로 학습을 해서 모델이 한 단계씩 논리적으로 생각하면서 답변을 하도록 하는 것도 환각을 줄이기 위한 방법 중 하나입니다.
환각의 유형
환각은 크게 아래 두 가지 유형으로 나눌 수 있습니다.
1. Intrinsic Hallucination(내재적 환각)
모델이 생성한 답변이 논리적으로 맞지 않거나 일관성을 갖지 못 경우입니다.
- 사용자: 베이징은 중국의 수도인가요?
- 모델: 중국의 수도는 베이징이며 대한민국에 위치하고 있습니다. → 중국의 수도가 베이징인 것은 맞지만 중국의 수도이기 때문에 대한민국에 있을 수 없습니다.
2. Extrinsic Hallucination(외재적 환각)
모델이 생성한 답변이 자연스럽지만 실제 사실과는 다른 경우입니다.
- 사용자: 2002년 월드컵에서 결승전에 올라간 나라는 어디인가요?
- 모델: 2002년 월드컵에서는 브라질과 대한민국이 각각 튀르키예와 독일을 꺾고 결승전에 진출하였습니다. → 브라질이 튀르키예를 이긴 것은 맞지만 대한민국은 독일에 패해 결승전에 진출하지 못했습니다.
여기서 Extrinsic Hallucination(외재적 환각)은 좀 더 상세하게 나눠집니다.
2-1. Fabrication Hallucination(날조 환각)
존재하지 않는 인물, 문서, URL 등을 지어내는 환각입니다.
- 모델: 칼 마르크스는 1873년 노동(Die Arbeit)이라는 책을 출판했습니다. → 오류인 이유: 칼 마르크스는 자본(Das Kapital)을 출판했습니다.
2-2. Contextual Hallucination(문맥 환각)
대화의 맥락과 맞지 않는 환각입니다.
- 사용자: 이번에 팀 쿡이 발표한 아이폰에 대해 알려주세요.
- 모델: 팀 쿡은 미국의 유명한 영화 감독으로 아이폰을 이용해 단편 영화를 촬영하였습니다. → 오류인 이유: 팀 쿡은 애플의 CEO인데 영화 감독으로 잘못 대답을 했습니다.
2-3. Overgeneralization Hallucination(과도한 일반화 환각)
일부 사례를 근거로 전체를 일반화하는 환각입니다.
- 모델: 중남미 나라들의 공용어는 모두 스페인어입니다. → 오류인 이유: 브라질은 포르투갈어, 수리남은 네덜란드어, 벨리즈와 가이아나는 영어가 공용어입니다.
2-4. Compression Hallucination(압축 환각)
긴 텍스트를 요약할 때 핵심 정보를 누락하거나 잘못 요약하는 환각입니다.
- 예시: 프랑스와 독일은 친선 축구 경기에서 치열한 승부를 펼친 끝에 프랑스가 승부차기에서 4:3으로 승리하였습니다.
- 모델: 독일은 프랑스와의 축구 경기에서 승리했습니다. → 오류인 이유: 독일이 아니라 프랑스가 축구 경기에서 승리했습니다.
2-5. Statistical Hallucination(통계적 환각)
통계나 숫자 정보를 신뢰성 있는 것처럼 제시하지만 실제로는 부정확한 경우입니다.
- 모델: 대한민국의 도시화율은 25.369%입니다. → 오류인 이유: 대한민국의 도시화율은 약 90%입니다.
환각 정도를 측정할 수 있을까?
공개된 LLM을 바로 쓸 수도 있지만 특정 목적에 따라 데이터셋을 구축해 미세조정(finetuning)해서 쓰는 경우가 많습니다. 이렇게 만든 LLM에서 환각 현상이 빈번하게 발생한다면 서비스 신뢰도는 크게 하락할 것입니다.
HalluLens2)에서는 LLM의 환각 정도를 측정하기 위해 다음과 같은 방법을 제안하고 있습니다.
1. PreciseWikiQA
- LLM이 짧고 사실적인 답변을 하는지 질문을 해서 답변을 평가합니다.
- 질문은 평가 대상 LLM이 아닌 다른 LLM을 이용해 위키피디아에서 5,000개의 주제를 선정해 질문과 답변을 임의로 생성하도록 합니다. 동적으로 만들기 때문에 평가를 할 때마다 질문과 답변이 달라질 수 있습니다.
- 평가 대상 LLM의 답변은 질문을 만든 LLM이 답변과 얼마나 일치하는지 비교해서 정확도를 계산합니다.
- 평가 메트릭으로는 거짓 거부율(False refusal rate), 거부하지 않았을 때의 환각율(Hallucination rate, when not refused), 정답률(Correct answer rate)이 있습니다.
2. LongWiki
- 위 PreciseWikiQA와 방법이 유사하지만 평가 대상 LLM이 긴 글을 생성할 때 얼마나 일관성을 가지고 문맥을 이해하는지 평가합니다.
- 평가 메트릭으로는 거짓 거부율(False refusal rate), 정밀도(Precision), 재현율@K, F1@K가 있습니다.
3. NonExistentRefusal
- LLM이 학습한 데이터셋에 없는 질문이 있을 경우 환각이 발생할 수 있는데 평가 대상 LLM에게 존재하지 않는 개체를 만들어 질문을 하였을 때 답변을 거부하는지 평가합니다.
- 평가 메트릭으로는 거짓 수용률(False acceptance rate)이 있습니다.
LLM이 생성하는 답변에 얼마나 환각이 있는지는 정확하게 알기 어려웠습니다. HalluLens에서는 이를 객관적으로 평가하고 계산해 볼 수 있도록 다각도의 벤치마크 방법론을 만들었다는 점에서 의의가 있습니다. 글로벌 IT 기업뿐만 아니라 작은 기업들도 목적에 맞게 LLM을 만들어 공개하고 있는데 이러한 벤치마크 테스트를 진행해 보는 것도 LLM의 성능을 높이는 데 도움이 될 것입니다.
|
|
|
정부가 추진하는 ‘독자 AI 파운데이션 모델 프로젝트’가 본격화되었습니다. 10개 이상의 컨소시엄이 접수를 준비하며 수주전이 활발하게 전개되고 있는데요. 컨소시엄은 AI 풀스택을 아우르는 구조로 구성돼 인프라 구축부터 모델 개발·서빙·서비스화까지 수행할 수 있는 팀이 유리하며, 대학·대학원생 참여도 필수입니다. 개발 모델은 해외 모델 파인튜닝이 아닌 국산 설계 기반이어야 하며, 글로벌 수준 대비 95% 이상 성능을 달성하는 것이 목표입니다. 선정된 팀은 최대 3년간 약 2,136억 원 규모의 정부·민간 공동 자금을 지원받으며, 단계별 평가를 통해 성과에 따라 압축될 예정입니다.
마크 저커버그 메타 CEO는 스마트 안경을 포스트 스마트폰 시대의 핵심 디바이스로 지목하며, 미래에는 스마트 안경이 없으면 인지적 불리함을 겪는 시대가 올 것이라고 전망했습니다. 메타는 레이밴과 협력해 출시한 ‘레이밴 메타 안경’으로 200만 대 이상 판매고를 올렸고, 이후 고급형 AR 안경 ‘하이퍼노바’를 2027년 출시 목표로 개발 중입니다. 구글의 경우 과거 사생활 침해 논란과 낮은 실용성 문제로 글래스 사업에 실패했으나, 최근 AI 기술에 기반한 스마트 안경은 실용성을 강조하며 시장 반응을 끌어내는 데 집중하고 있습니다. 애플은 경량형 AI 기반 안경을 개발 중이며, 삼성전자와 구글은 안드로이드 XR 기반 제품을 2025년 출시 예정이며, 바이트댄스도 초경량 XR 안경을 준비하고 있습니다.
미국 법원은 최근 판결에서 생성형 AI가 저작권자의 동의 없이 저작물을 학습한 행위를 ‘공정 이용’으로 인정하며, AI 학습과 저작권 충돌에 있어 기술 기업의 손을 들어주는 분위기입니다. 법원은 AI 학습 행위와 데이터 확보 방식을 구분해 판단했으며, 불법 복제된 책을 사용한 것은 침해로 보되 학습 자체는 ‘변형적 사용’으로 합법이라 판단했습니다. 국내에서도 네이버가 뉴스 콘텐츠를 AI 모델에 무단 활용했다며 지상파 3사와 신문협회가 저작권 침해 소송을 제기한 가운데, 여기에 미국 판례가 영향을 미칠지 주목됩니다. 네이버는 제휴 약관에 따른 정당한 학습이라는 입장이지만 언론사는 해당 약관이 AI 학습까지 포함하지 않는다며 별도 동의가 필요하다는 입장입니다.
|
|
|
플리토는 과학기술정보통신부와 NIPA가 주관하는 ‘AI·디지털 비즈니스 파트너십 특화 프로그램’을 통해 미국 동부 시장 진출에 집중하고 있습니다. 이 프로그램은 글로벌 진출을 희망하는 국내 AI·디지털 기업에게 현지 네트워크 및 컨설팅을 지원하는 정부 지원 사업인데요. 플리토는 뉴욕대(NYU)와의 협력을 통해 최근 열린 ‘NYU AI 네트워킹의 밤’ 행사 등에서 AI 동시통역 솔루션을 제공하기도 했습니다. 이번 협업은 플리토의 AI 언어 데이터 기술력을 미국 시장에 알리는 중요한 계기가 될 것으로 기대가 되고 있습니다. 플리토는 AI·디지털 비즈니스 파트너십 특화 프로그램을 통해 미국 시장에서의 사업 기회를 적극적으로 모색함으로써 글로벌 AI 언어 데이터 시장을 선도하는 기업으로 도약할 계획입니다.
|
|
|
플리토는 자사 앱 내 음성 데이터 수집 기능인 ‘아케이드 토킹 미션’을 고도화했습니다. 이를 통해 실제 통화 환경에 가까운 고품질 음성 데이터를 안정적으로 수집·가공할 수 있는 체계를 완성했는데요. 이번 프로젝트는 글로벌 빅테크 수요에 기반해 기획된 것으로, 다양한 AI 모델의 고도화를 위한 정밀 학습용 음성 데이터 확보에 초점을 맞추고 있습니다. 해당 미션은 별도 앱이나 통화 연결 없이 앱 내에서 자유롭게 통화하며 데이터를 수집하는 구조입니다. 이번 고도화를 통해 플리토는 데이터 수집부터 가공, 라벨링, 제출까지 원스톱 인프라를 정비하며 전 주기에 걸친 데이터 품질 관리 시스템을 구축했습니다. 수집된 데이터는 빅테크와 연구기관에 공급되며, 플리토는 이를 통해 글로벌 AI 산업의 정밀화와 언어 다양성 확대에 기여할 예정입니다.
|
|
|
Beyond Language Barriers!
|
|
|
플리토 (Fliitto Inc.)
서울 강남구 영동대로96길 20 대화빌딩 6층
|
|
|
|
|