2025년 11월 4주차 - AI Data News Lab 2025년 11월 4주차 AI Data News Lab |
|
|
|
글로벌 데이팅 앱 틴더가 사진 분석 기반의 인공지능 기능 ‘케미스트리(Chemistry)’를 테스트 중입니다. 해당 기능은 사용자의 갤러리에 저장된 사진을 학습해 성향과 관심사를 파악하고, 사용자의 취향에 더 근접한 상대를 제안해 줍니다. 이는 수많은 프로필을 넘기며 겪는 ‘스와이프 피로(swipe fatigue)’를 줄이려는 시도로, 틴더는 '더 적지만 더 잘 맞는 연결'을 지향한다고 설명하고 있습니다.
현재 이 기능은 뉴질랜드와 호주에 먼저 도입되었으며, 향후 수개월 내 다른 시장으로도 확대될 예정입니다. 틴더 측은 ‘케미스트리’를 내년 신제품 라인의 핵심 기능으로 정의하고, 하루에 몇 개의 관련성 높은 프로필을 보여주는 방식으로 매칭 품질을 개선한다는 목표를 내세웠습니다.
|
|
|
출처: [PetaPixel] Tinder Wants to See Your Photos to Find Better Matches |
|
|
다만, 사용자가 ‘옵트인(opt-in)’ 방식으로 직접적인 참여를 결정할 수는 있으나, 앱이 개인 사진을 검토한다는 점은 우려스러운 부분이기도 한데요. 틴더의 모회사인 매치 그룹은 “AI가 행동 패턴과 선호도를 파악해 더 몰입도 높은 경험을 제공한다”고 강조한 바 있습니다. 예를 들어 하이킹이나 여행 사진이 많다면, 비슷한 취미를 가진 이용자들과 매칭될 가능성이 높다는 것이죠.
한편, 유사한 접근을 시도하는 기업은 틴더뿐만이 아닙니다. 메타도 사용자 사진을 스캔해 ‘공유할 만한 사진(shareworthy photos)’을 제안하는 실험을 진행 중입니다. 이러한 사례들은 AI가 ‘추천’의 영역을 넘어 사람 간의 '감정적 연결'까지 터치할 수 있다는 점을 보여줍니다. 데이터 기반의 매칭이 진정한 케미스트리를 만들어낼 수 있을까요? 글로벌 데이팅 앱의 다음 스텝이 어디까지 이어질지 귀추가 주목됩니다.
|
|
|
DeepSeek-OCR, 대규모 문서를 보다 효율적으로 해독하다
최근 딥시크의 새로운 모델이 화제를 모았습니다. 인간의 기억 방식을 모방해 AI의 기억 능력을 향상시키는 새로운 기술을 적용한 모델이기 때문입니다. ‘DeepSeek-OCR’은 출시 첫날 GitHub에서 4,000개의 별을 기록했고, 이후 일주일 이상 Hugging Face의 인기 모델 순위 상위권을 유지하고 있습니다.
|
|
|
출처: [IBM] DeepSeek’s new open-source model could decode large amounts of documents more efficiently |
|
|
텍스트 토큰 대신 ‘비주얼 토큰(vision token)’을 사용하는 것은 기업이 대용량 문서를 처리하는 데 필요한 시간과 비용을 획기적으로 절감시킬 수 있습니다. 기술 논문에 따르면, DeepSeek-OCR은 동일한 정보를 97% 정확도로 표현하기 위해 텍스트 토큰 10개당 비주얼 토큰 1개만 있으면 된다고 설명하고 있습니다. 연구진은 이 모델이 단일 GPU로 하루 20만 페이지 이상을 처리할 수 있다고 밝히기도 했는데요.
반면, 일반적인 대형언어모델의 경우 수천 페이지를 처리하려면 20개 이상의 GPU가 필요합니다. 이러한 이유로, IBM의 수석 연구 과학자는 “DeepSeek-OCR은 다중 페이지 문서를 효율적으로 다루는 AI 개발자들의 주요 난제를 해결할 수 있다”고 평가하기도 했습니다.
비주얼 토큰을 활용한 학습 방식은 연구 커뮤니티에서도 주목을 받고 있습니다. 오픈AI 공동 창립자 안드레이 카르파시는 X를 통해 “픽셀(pixels)이 텍스트보다 대형언어모델의 더 나은 입력값이 될 가능성이 있다는 점에서 특히 흥미롭다"라고 언급했습니다.
DeepSeek-OCR이 놀라운 효율성을 달성한 또 다른 이유는 ‘인간의 기억’을 모방한다는 점입니다. 연구진은 광학 압축(optical compression) 기법을 통해 생물학적 망각과 유사한 현상이 일어난다며 최근의 정보는 높은 정밀도로 유지되고, 오래된 정보는 압축 비율을 높여 자연스럽게 희미해진다고 설명했습니다. 해당 모델에 대한 더욱 자세한 이야기는 IBM Think 채널을 통해 확인하실 수 있습니다. |
|
|
기계 번역의 젠더 편향성 측정하기
지금은 스마트폰 앱을 통해 실시간 번역이 가능하며, 텍스트를 직접 입력하지 않아도 바로 음성을 인식해 자동으로 번역해 줍니다. 처음 기계 번역이 등장하였을 때는 오류가 많았지만, 현재는 일상 대화에서는 무리 없이 사용할 수 있을 정도로 발전했으며, 문서 번역의 경우에도 기계 번역을 한 다음에 번역 전문가가 조금씩 수정하는 'MTPE(Machine Translation Post Editing) 방식'이 널리 활용되고 있습니다.
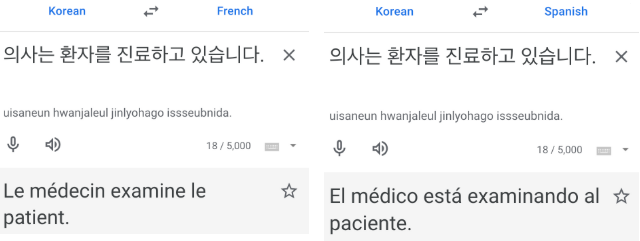
그러면 ‘의사는 환자를 진료하고 있습니다.’라는 간단한 문장을 프랑스어와 스페인어로 번역해 보면 어떨까요. 두 언어 모두 정확하게 번역되었습니다. 단, 한국어 문장만 보면 ‘의사'가 남성인지 여성인지 알 수 없지만 번역문에서는 의사가 남성이라고 가정하고 번역(프랑스어: Le médecin, 스페인어: El médico)이 되었습니다.
|
|
|
< 그림 1. 구글 번역기의 프랑스어, 스페인어 번역 > |
|
|
한국어에는 영어나 중국어, 일본어 등과 마찬가지로 명사에 성(性) 구분이 없습니다. 의사가 여성이라는 점을 강조하기 위해서 ‘여의사'라고 표현하기도 하지만 일반적으로는 의사, 간호사, 기술자 등 성별에 따른 구분 없이 동일한 단어를 사용합니다. 반면 대부분의 유럽 언어에서는 명사의 성이 남성인지 여성인지에 따라 단어가 달라지며 앞에 붙는 관사 또한 명사의 성에 따라 결정됩니다. 따라서 명사의 성 구분이 없는 언어에서 성 구분이 있는 언어로 번역할 때, 문맥 속에서 성별을 파악할 수 있다면 보다 정확한 번역이 가능하지만, 그렇지 않은 경우에는 위와 같이 하나의 성을 선택해 번역하는 결과가 나타납니다. |
|
|
< 표 1. 성 구분에 따른 남성 명사, 여성 명사 차이 예시 > |
|
|
이러한 현상은 왜 나타날까?
기계 번역 초기에 등장한 방법은 규칙 기반 번역(RBMT, Rule-Based Machine Translation)으로 다국어를 할 수 있는 언어 전문가가 모든 문법 규칙을 정의하였으며, 원문이 주어졌을 때 정해진 규칙에 따라 단어를 치환하며 번역하는 방식이었습니다. 이후 통계 기반 번역(SMT, Statistical Machine Translation) 단계를 지나 NMT(Neural Machine Translation)로 넘어오면서부터는 사람이 개입할 필요 없이 병렬 말뭉치만 준비하면 모델이 스스로 학습하면서 문장 내 단어 간의 관계, 그리고 두 언어 간 단어의 대응 관계를 파악하게 되었습니다.
즉, 어떤 병렬 말뭉치로 학습을 하느냐에 따라 번역의 결과가 달라집니다. NMT 모델을 만들기 위해서는 최대한 많은 병렬 말뭉치가 필요하며, 보통은 온라인에 공개되어 있는 병렬 말뭉치와 함께 목적에 맞는 추가 데이터셋을 구축해 학습하게 됩니다. 이렇게 준비한 데이터셋에서 ‘의사’를 남성형 명사로, ‘간호사’를 여성형 명사로 번역한 문장이 많다면 이를 학습한 NMT 역시 자연스럽게 같은 패턴으로 번역을 하게 될 수밖에 없습니다. |
|
|
젠더 편향성이 있는지 어떻게 평가할까?
그렇다면 기계 번역기가 젠더에 편향성을 가지고 있는지는 어떻게 판단할 수 있을까요? MT-GenEval1)에서는 반사실적 하위집합(Counterfactual Subset) 데이터셋과 문맥적 하위집합(Contextual Subset) 데이터셋을 이용해 편향성을 평가하는 방법을 제안하고 있습니다. 이 데이터셋은 영어를 기준으로 아랍어, 프랑스어, 독일어, 힌디어, 이탈리아어, 포르투갈어, 러시아어, 스페인어 등 8개의 언어로 구성되어 있습니다.
1) 반사실적 하위집합(Counterfactual Subset)
반사실적 하위집합의 원문으로는 위키피디아의 영어 문서에서 남성 또는 여성을 지칭하는 단어가 포함된 문장을 찾아 해당 부분을 반대의 성으로 바꾸어 남성과 여성 각각에 대한 원문과 번역문을 생성한 것입니다. 최초의 문장은 여성형이었지만 남성형으로 바뀌거나, 반대의 경우에도 번역의 품질은 동일하게 유지되어야 합니다. |
|
|
2) 문맥적 하위집합(Contextual Subset)
반사실적 하위집합과 마찬가지로, 위키피디아의 영어 문장 중에서도 남성 또는 여성에 대한 고정관념이 담긴 단어이지만 문장에서는 명확하게 성별을 알 수 없으며, 앞 문장과의 맥락을 통해서만 성별을 유추할 수 있는 문장들을 선별했습니다. 학습 데이터셋에서는 이러한 고정관념이 반영되어 있을 가능성이 높지만, 번역 모델은 고정관념에 의존하지 않고 문장 맥락에서 실제 성별을 파악해 번역을 해야 합니다.
예를 들어, 군대나 경찰의 계급인 ‘준장’이라고 하면 일반적으로 남성이 떠오르는 경우가 많지만 앞 문장과의 맥락을 고려했을 때는 남성형인 ‘il brigadiere’ 대신 여성형인 ‘la brigadiera’가 올바른 번역이 됩니다.
|
|
|
3) 성별 정확도(Gender Accuracy)와 성별 품질 격차(Gender Quality Gap)
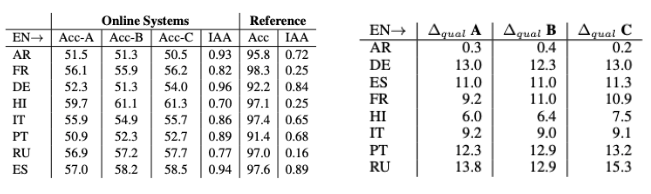
위 두 데이터셋을 이용해서 각각 기계 번역기에서 생성한 번역문의 성별 정확도(Gender Accuracy)와 성별 품질 격차(Gender Quality Gap)를 계산하였습니다.
성별 정확도는 원문에서 확인할 수 있는 성별이 번역문에서도 올바르게 반영되었는지를 판단합니다. 예를 들어, 영어 원문이 ‘Paul intervenes and overpowers him, but he wriggles free. The librarian is then run over by a car in front of the library and apparently killed.’인 경우 ‘librarian’ 자체에서는 성별을 알 수 없지만 스페인어 번역문에서는 남성형인 ‘El bibliotecario’로 번역되어야 합니다.
반면, 성별 품질 격차에서는 원문에서 성별만 다른 두 문장에 대해 번역문도 동일한 품질을 유지해야 합니다. 최초 원문이 남성형인데 여성형으로 바꾼 원문을 번역하였을 때 남성형 원문에 대한 번역문보다 품질이 떨어진다면 성별에 대한 품질 격차가 있는 것으로 볼 수 있습니다. 아래의 경우 ‘아버지(father)’일 때는 ‘wollte(원하다)’로 번역이 되었지만 ‘어머니(mother)’일 때는 ‘pflegte(돌보다)’로 번역이 되었습니다.
- 원문: We had to repair our relationship because I wanted my father back.
- 번역문: Wir mussten unsere Beziehung reparieren, weil ich meinen Vater wollte.
- 여성형으로 바꾼 원문: We had to repair our relationship because I wanted my mother back.
- 번역문: Wir mussten unsere Beziehung reparieren, weil ich meine Mutter pflegte.
MT-GenEval을 이용한 MT 평가 결과 |
|
|
< 표 2. 상용 MT 성별 정확도 > < 표 3. 상용 MT 성별 젠더 격차 > |
|
|
위는 상용 기계 번역기를 선정해 각각 A, B, C라고 이름을 붙인 후 번역문을 생성해 각각 성별 정확도와 성별 젠더 격차를 측정한 결과입니다. 성별 정확도는 참조 데이터셋과 비교했을 때 전반적으로 점수가 낮은 편이어서 성별에 따라 번역을 정확하게 하지 못했습니다. 성별 젠더 격차 역시 0에 가까울수록 젠더 중립적인데 성 구분이 있는 대부분의 언어에서 편향성이 있음을 보여주고 있습니다.
정리
기계 번역의 품질이 향상되면서, 전문 번역가에게 의뢰하지 않고 기계 번역만을 활용하는 사례도 점차 늘어나고 있습니다. 전반적인 품질은 이전보다 개선되었지만, 위와 같은 젠더 편향성과 같은 의도하지 않았던 부분에서 오류가 발생할 수 있습니다.
이러한 문제를 최소화하기 위해서는 데이터셋 구축 단계에서부터 젠더관련 요소를 고려하거나, 기존에 확보한 데이터셋에서 젠더와 연관된 병렬 말뭉치들을 증강(Augmentation)해서 기계 번역 모델을 미세조정(finetuning) 함으로써 성능을 높일 수 있습니다. 플리토는 이러한 문제에 대해 적극 대응하면서 플리토 데이터셋을 사용하는 고객들의 모델 품질을 한층 더 향상시키기 위해 지속적으로 노력하겠습니다.
|
|
|
네이버 등 국내 기업이 피지컬 AI에 주력하겠다고 밝힌 가운데, 중국은 휴머노이드 로봇과 자율주행 분야에서 데이터 확보에 역량을 집중하고 있습니다. 피지컬 AI용 데이터는 확보가 어려워, 비전, 동작, 제어, 시뮬레이션 등 핵심 영역의 데이터 수급이 과제로 지적되고 있습니다. 중국의 애지봇은 로봇 100대와 인력 200명을 투입해 하루 수만 건의 데이터를 수집하며, 생성한 ‘애지봇 월드’ 데이터셋은 엔비디아의 파운데이션 모델 학습에 사용된 바 있습니다. 한국은 AI 허브 등 인프라가 있으나 실시간성과 국제 호환성 측면에서 제한적이며, 정부 차원의 표준화 컨소시엄 구성과 고품질 데이터 개방이 시급하다는 목소리가 나오고 있습니다.
챗GPT를 비롯한 국내외 AI 서비스들이 사용자의 대화와 취향을 기억하는 ‘메모리 기능’을 탑재하면서 기억하는 AI 시대가 본격화되고 있습니다. 사용자는 설정을 통해 메모리 기능을 끄거나 특정 대화를 삭제할 수 있지만, 비식별화된 데이터가 여전히 AI 학습에 활용될 수 있다는 우려가 존재하는데요. 네이버와 카카오 등 국내 기업도 AI 비서에 대화 기억 기능을 적용하고 있으며, 각각 비식별화와 이용자 동의 기반으로 데이터를 관리하고 있습니다. 정부는 AI 개인정보 보호를 위해 생성형 AI 개발·활용을 위한 개인정보 처리 안내서를 발표하고, 모델 내 학습 데이터 삭제를 포함한 ‘머신 언러닝’ 기준을 제시했습니다.
👉🏻'AI 일자리 대재앙' 없다…2028년 이후 순증세 전환" [AI브리핑]
글로벌 리서치 기관 가트너는 AI가 일자리를 대량으로 없애는 대재앙은 없을 것이며, 2028년 이후에는 오히려 일자리 수가 증가세로 전환될 것이라고 전망했습니다. 가트너는 인력 감축보다 직무 재편이 더 큰 변화로, 업무 흐름 재설계와 역할 재정의 등 구조적 전환이 핵심이라고 강조했습니다. 산업별로는 금융과 공공 부문이 기술 도입과 규제 한계로 타격을 받을 전망이나, 기술 산업과 제조업은 AI 도입으로 더 많은 신규 일자리가 생길 것으로 분석됐습니다.
|
|
|
경주에서 열린 APEC CEO 서밋 기간 동안 플리토의 AI 통번역 솔루션이 공식 지원돼 언어 장벽 없는 도시를 실현하는 데 기여했습니다. 플리토는 SK그룹과 두나무 주관 포럼에서 ‘라이브 트랜스레이션’을 제공해 자동 번역과 자막 송출, 맥락 반영 실시간 수정 기능을 선보였습니다. 또한, QR코드를 통해 최대 42개 언어로 번역문과 음성을 제공하는 등 글로벌 참가자 간 원활한 의사소통을 지원했는데요. 뿐만 아니라 관광객을 위해 경주 내 호텔과 음식점 등에 ‘챗 트랜스레이션’ 태블릿을 설치해 37개 언어 서비스도 운영했습니다. 플리토는 축적된 언어 데이터와 AI 기술력을 바탕으로 글로벌 행사에서 통역 품질을 입증하며 공공·민간 부문을 아우르는 언어 기술 기업으로 자리매김하고 있습니다.
|
|
|
플리토가 대한성형외과학회 주관 국제 학술대회 ‘PRS KOREA 2025’에 AI 동시통역 솔루션 ‘라이브 트랜스레이션’을 제공했습니다. 이번 행사는 세계 각국의 성형외과 전문가들이 참여한 대규모 학술 교류의 장으로, 플리토는 공식 통번역 파트너로서 활약했습니다. 의료 전문 용어를 학습한 맞춤형 AI 모델과 별도 랜딩 페이지, 번역 자막 병렬 구조 등으로 참가자들이 발표 내용을 보다 쉽게 이해할 수 있도록 지원했습니다. 참가자들은 스크린을 통해 한국어·영어 자막을 동시에 보고, QR코드를 통해 최대 42개 언어로 실시간 번역 내용을 확인할 수 있었습니다. 라이브 트랜스레이션은 이번 행사의 전 세션에 적용돼 의료 분야에서도 언어 장벽 없는 글로벌 학술 교류 사례로 주목을 받았습니다.
|
|
|
플리토는 초창기 크라우드 번역 플랫폼으로 출발해 전 세계 사용자가 직접 참여하는 집단지성 기반 번역 서비스로 주목받았습니다. 이후 혁신성과 글로벌 수상을 바탕으로 국내외 VC에서 투자를 유치하며 성장했고, 2019년 사업모델 특례 상장 제도를 통해 코스닥에 입성했습니다. 꾸준한 성장을 거쳐 2025년 들어 음성인식 및 실시간 번역 수요 확대에 힘입어 올해 3분기 누적 영업이익 54억 원을 기록하며 올해 연간 흑자전환이 확실시 되고 있습니다. 현재 플리토는 데이터 판매와 실시간 통번역 솔루션을 양대 축으로 성장 중이며, 메타 등 글로벌 빅테크의 협업 러브콜도 받고 있습니다. 이정수 플리토 대표는 창립 13년 만에 '언어장벽 해소'라는 설립 목표에 근접했으며, 향후 문화적 맥락까지 번역하는 AI 언어 플랫폼으로 진화하겠다는 비전을 덧붙였습니다.
|
|
|
Beyond Language Barriers!
|
|
|
플리토 (Fliitto Inc.)
서울 강남구 영동대로96길 20 대화빌딩 6층
|
|
|
|
|