2025년 12월 3주차 - AI Data News Lab 2025년 12월 3주차 AI Data News Lab |
|
|
|
구글이 제미나이 3 기반의 이미지 생성 모델 '나노 바나나 프로'를 활용한 연말 캠페인 영상 '산타 이즈 커밍 투 타운'을 공개했습니다. 이번 프로젝트는 돌고래유괴단의 신우석 감독이 연출을 맡았으며, 배우 윤경호, 변우석, 박희순이 등장해 연말 특유의 따스한 분위기를 전했습니다.
총 2개로 나누어진 캠페인 영상은 AI가 우리의 일상을 어떻게 특별한 추억으로 바꿀 수 있는지 감성적인 메시지를 잘 담아내고 있는데요. 지난 5일 선공개된 '아빠의 퇴근길'과 추가로 새롭게 공개된 '크리스마스의 비밀'은 공개되자마자 온오프라인 관계없이 높은 호응을 끌어내고 있습니다. 두 영상 모두 크리스마스를 배경으로 제미나이가 일상 속 따뜻한 감정에 스며드는 순간을 잘 담아냈다는 평이 이어지고 있죠.
|
|
|
특히 가장 먼저 공개된 '아빠의 퇴근길' 편은 평범한 하루 속에 찾아온 기적 같은 순간을 제미나이로 따뜻하게 완성했는데요. 퇴근길에 우연히 루돌프와 썰매를 발견한 아빠가 엘리베이터 앞에서 산타를 마주치며 특별한 인사를 주고받고, 그 짧은 순간을 아들과도 공유하고 싶었던 그는 제미나이를 통해 산타와 함께 찍은 듯한 사진을 만들어 아들에게 보여줍니다.
구글의 '산타 이즈 커밍 투 타운' 캠페인은 단순히 AI 기술을 시연하는 데 그치지 않고, AI 기술이 우리의 일상 속에 다양한 방식의 온기를 더할 수 있음을 보여주고 있는데요. 다양한 AI 모델을 통해 올겨울이 지나기 전에 주변에 그동안 전하지 못한 마음을 따뜻한 연말 메시지로 전달해 보는 건 어떨까요?
|
|
|
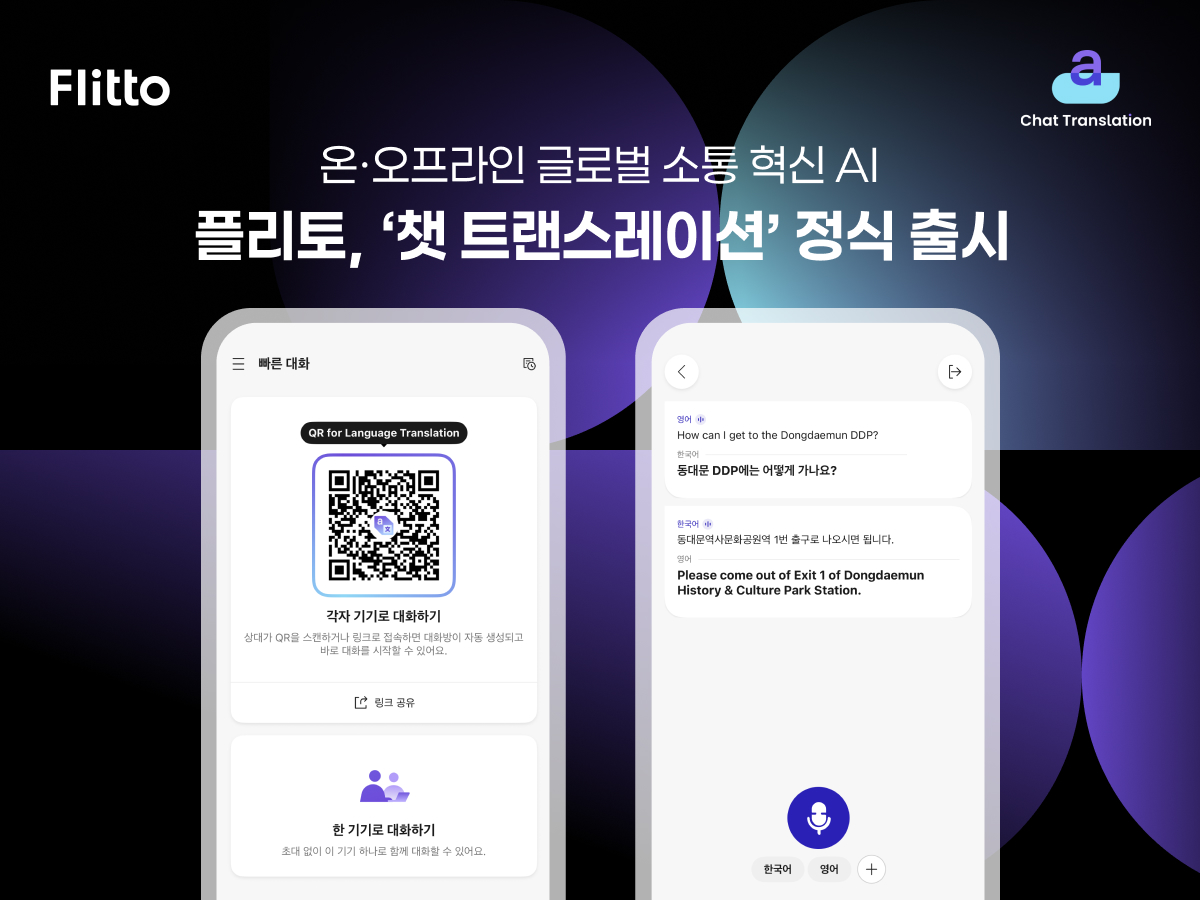
세상에 하나뿐인 나만의 AI 통번역 앱 '챗 트랜스레이션' 공식 출시
플리토가 다년간 축적한 고품질 언어 데이터와 STT(Speech-to-Text) 기술을 결합한 차세대 AI 통번역 솔루션 '챗 트랜스레이션(Chat Translation)'의 정식 버전을 지난 10일 출시했습니다. 챗 트랜스레이션은 온·오프라인 어디서나 언어 장벽 없이 몰입도 높은 대화 환경을 제공하며, 최대 37개 언어를 지원합니다.
특히, 사용자를 이해하는 '초개인화(Hyper-Personalization)'를 통해 단순히 언어를 변환하는 것을 넘어, 사용자의 의도와 맥락을 함께 이해하는 차별화된 AI 통번역 서비스를 제공한다는 점이 특징인데요. 플리토의 AI 시스템은 사용자가 원하는 정보를 데이터셋으로 등록하면 이를 바탕으로 언어 습관 등을 분석한 후 보다 정확하고 자연스러운 맞춤형 번역을 제공합니다. |
|
|
챗 트랜스레이션은 여행, 일상 대화부터 비즈니스까지 폭넓게 활용할 수 있습니다. 글로벌 바이어와의 상담, 해외 전시회에서의 실시간 다국어 소통, 다국적 팀 회의, 오프라인 매장에서의 외국인 고객 응대 등 다양한 상황에서 자연스럽고 정확한 번역을 제공할 수 있습니다.
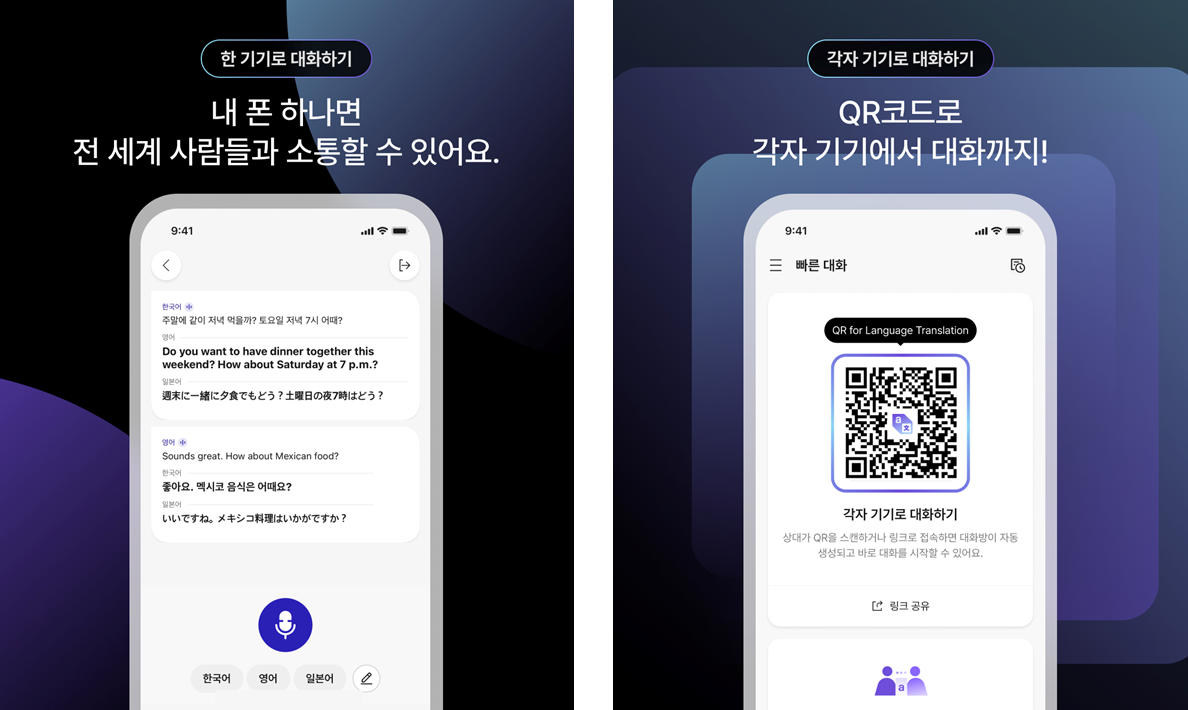
지난 10월 공개한 바 있는 베타 버전과 비교했을 때, 이번 정식 버전에서 가장 눈에 띄는 핵심적인 부분은 무엇보다도 새롭게 추가된 '빠른 대화(Quick Chat)' 기능입니다. 이 기능은 '대면 대화'와 'QR 대화' 두 가지 방식으로 구성되어 있는데요. 사용 환경에 따라 가장 적합한 방식을 선택해 유연하게 선택할 수 있습니다. |
|
|
'대면 대화'는 '한 기기로 대화하기'에서 가능합니다. 한 기기로 대화하기는 호스트 기기 하나만 있어도 여러 명의 사용자가 동시에 사용할 수 있습니다. 단일 기기에서 최대 3개 언어를 자동 인식해 실시간으로 번역하며, 복수 언어가 섞여도 자연스럽게 구분이 가능합니다.
'QR 대화'는 '각자 기기로 대화하기'에서 할 수 있는데요. 호스트 기기의 QR코드를 각자의 기기로 스캔만 하면 원하는 언어를 선택해 대화할 수 있는 기능입니다. 최대 10명까지 참여 가능하며, 해당 대화의 경우 비즈니스 상황에서 특히 유용합니다. 자주 사용하는 문구를 미리 저장해 두면 필요할 때마다 터치 한 번으로 빠르게 전송할 수 있기 때문이죠.
|
|
|
2. 데이터셋을 통한 초개인화(Hyper-Personalization) |
|
|
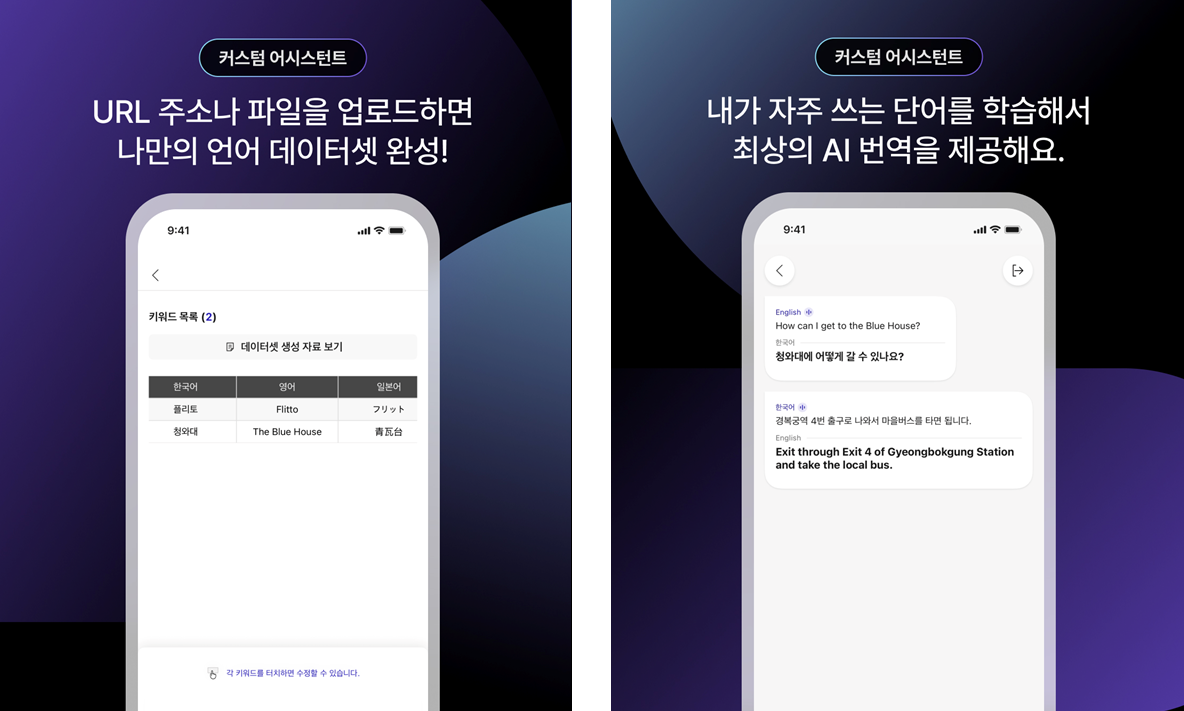
무엇보다 챗 트랜스레이션의 가장 큰 강점은 '초개인화(Hyper-Personalization)'입니다. 사용자는 업무 문서, 논문, 링크드인 프로필, 유튜브 채널 등 자신과 관련된 자료를 업로드해 개인 데이터셋을 구축할 수 있는데요. 이를 통해 사용자의 언어 습관과 표현을 학습하여 점점 더 정확하고 자연스러운 번역을 제공합니다.
예를 들어, '청와대'를 데이터셋으로 생성해 두면, 'Cheong Wa Dae'보다는 외신에서 주로 사용하는 'The Blue House'로 번역된 결과를 볼 수 있다는 겁니다. 추가로, 배우 '마동석'은 영어 이름으로 '돈 리(Don Lee)'를 사용하고 있는데요. 데이터셋을 생성하면 커스터마이징을 통해 개인화된 번역이 가능해 집니다. 따라서 한국어로 '마동석입니다'라고 얘기했을 때 'Dong-seok Ma'가 아닌 'Don Lee'로 이름이 번역되는 거죠.
플리토는 챗 트랜스레이션이 글로벌 커뮤니케이션의 새로운 표준으로 자리 잡을 것으로 기대하고 있습니다. 이를 통해 누구나 실시간으로 소통할 수 있는 환경을 제공함으로써, 일상 대화부터 글로벌 비즈니스 미팅까지 생산성과 효율성을 동시에 높이는 데 적극 기여할 계획입니다. 빠르고 정확한 초개인화 AI 통번역 앱 챗 트랜스레이션은 앱 스토어에서 누구나 무료로 다운로드할 수 있습니다. |
|
|
아프리카 소수 언어 번역기 만들기
구글 번역은 200여 개가 넘는 언어를 지원합니다. 한국어, 영어, 러시아어, 프랑스어, 스페인어, 아랍어, 중국어 등 주요 언어뿐만 아니라 압하지야어, 아체어, 그린란드어, 타히티어 등 일상에서 접하기 어려운 언어도 번역할 수 있습니다. 마이크로소프트 빙(Bing) 번역 역시 170여 개 이상의 언어를 지원하는데 특이하게 스타트렉(Star Trek)에 등장하는 외계 언어 중 하나인 클링온어(Klingon)1)도 지원합니다.
|
|
|
< 그림 1. 구글 번역 및 마이크로소프트 빙(Bing) 번역 지원 언어 >
|
|
|
지원하는 언어가 200여 개에 달하지만 인류가 쓰는 언어는 8,000개가 넘습니다. 즉, 7,800여 개 이상의 언어는 기계 번역기를 이용할 수 없습니다. 아프리카에서 사용되는 언어만 해도 2,000개가 넘는데 스와힐리어나 요루바어처럼 비교적 화자가 많은 언어들을 제외하면 NLP(Natural Language Processing) 연구조차 거의 진행되고 있지 않으며, 800개 이상의 언어가 사라질 위험에 처해 있다고 합니다.
기계 번역기를 만들기 위해서는 양질의 병렬 말뭉치가 대량으로 필요합니다. 주요 언어도 좋은 데이터셋을 만들기 쉽지 않은데 소수 언어라면 더욱 어렵습니다. 다행히 최근 등장한 LLM은 대량의 언어 데이터를 기반으로 학습하기 때문에, 직접 학습하지 않은 언어라도 유사한 언어가 학습이 되었다면 전이 학습(Transfer Learning) 효과를 통해 데이터셋이 적은 언어도 일정 수준까지 성능이 향상될 수 있습니다.
'A Collaborative Approach to Advancing Low-Resource African NLP'2)에서는 아프리카의 소수 언어 데이터를 어떻게 수집해서 LLM에 학습하였으며 기계 번역기를 어떻게 만들었는지 설명하고 있습니다.
아프리카 소수 언어 데이터 수집하기
LLM을 학습하기 위해 가장 필요한 것은 데이터입니다. LLM이 해당 언어를 이해하기 위해서는 소설이나 인문, 사회, 과학 등 그 언어 자체로 쓰인 다양한 텍스트를 기반으로 학습해야 합니다. 이러한 과정을 통해 문장 내 단어들이 서로 어떤 관계가 있는지, 앞 문장과 뒤 문장과는 어떻게 연결되는지 구조를 파악할 수 있습니다. 이후 다른 언어와의 병렬 말뭉치로 학습을 하게 되면 한 언어에서 다른 언어로의 번역이 가능해집니다.
|
|
|
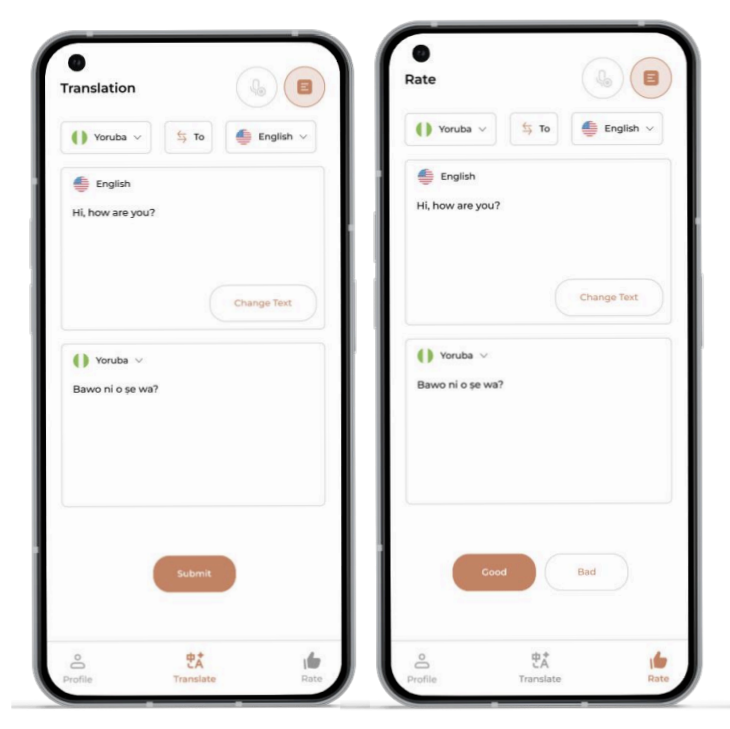
이 논문에서 데이터를 수집하기 위해서 사용한 방식은 크라우드소싱입니다. 연구팀은 'All Voices'라는 플랫폼을 만들었는데 스크린샷을 보면 플리토에서 아케이드를 통해 데이터를 수집하는 방법과 거의 흡사합니다. 플리토의 서비스와 비교하기 위해 앱을 다운로드 받으려고 하였으나 아쉽게도 현재는 앱을 찾아볼 수 없었습니다.
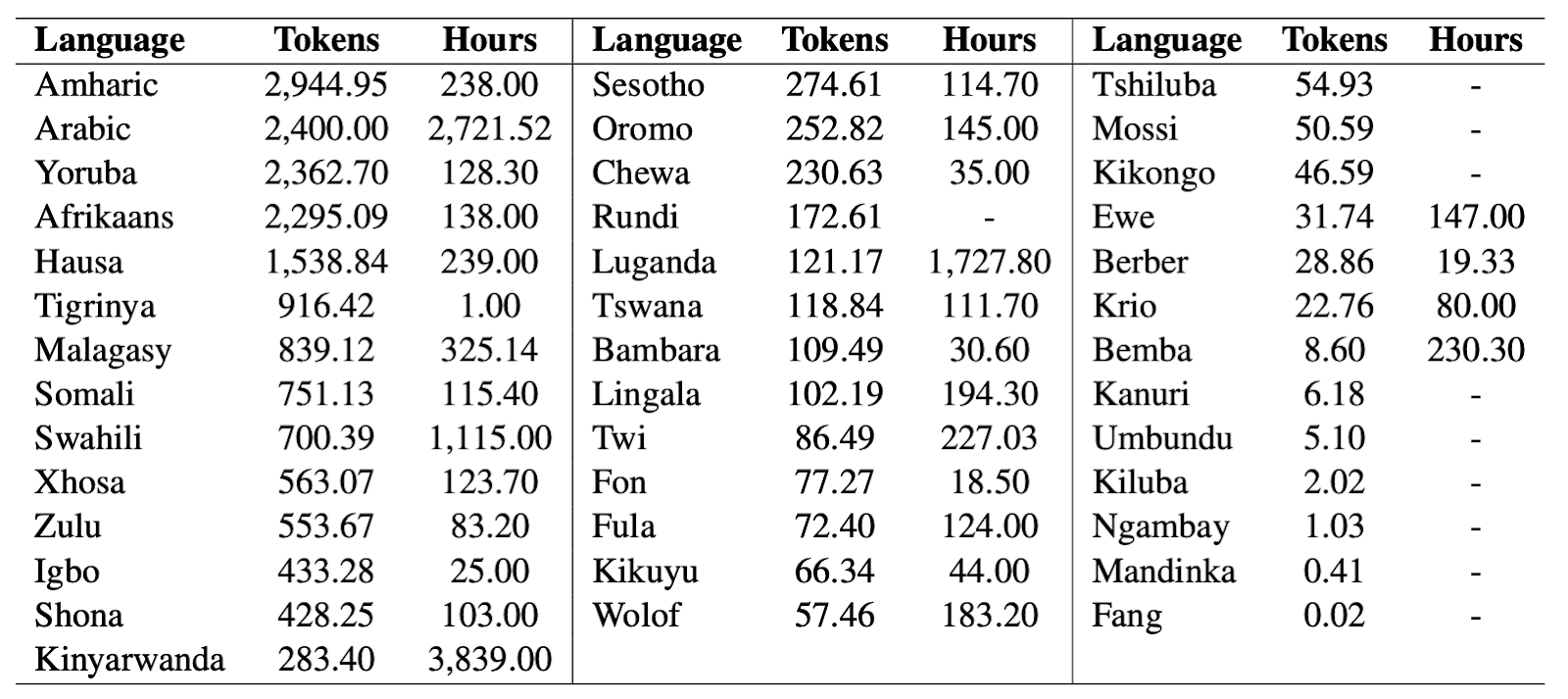
이 앱을 통해 수집한 데이터 현황은 아래와 같습니다. 아프리카 소수 언어 중에서도 화자가 많은 암하릭어나 요루바어, 아프리칸스어 등은 수집한 양이 많은 반면 그렇지 않은 언어는 거의 학습하기 어려울 정도로 양이 적다는 것을 확인할 수 있습니다.
|
|
|
학습하기
아프리카 소수 언어를 학습하기 위한 파운데이션 모델로 메타에서 공개한 Llama-3.2 1B 모델을 사용하였습니다. 최근에는 수천억 개 이상의 매개변수를 가진 모델도 널리 사용되고 있지만 10억 개의 매개변수라면 다소 작게 느껴질 수 있습니다.
LLM의 매개변수가 많을수록 학습 시간이 오래 걸리고, 매개변수 개수 대비 학습 데이터셋이 적으면 학습의 효과가 제대로 나타나지 않을 수 있습니다. 또한 범용적으로 다양한 작업을 수행해야 하는 대규모 LLM과는 달리 기계 번역기는 번역 기능만 정확하게 수행하면 되기 때문에 매개변수가 1B인 모델로도 충분합니다. 본 연구에서는 학습 인스트럭션으로 “Translate the following English text to X :“ (X는 아프리카 소수 언어)를 사용하였습니다.
품질 평가하기
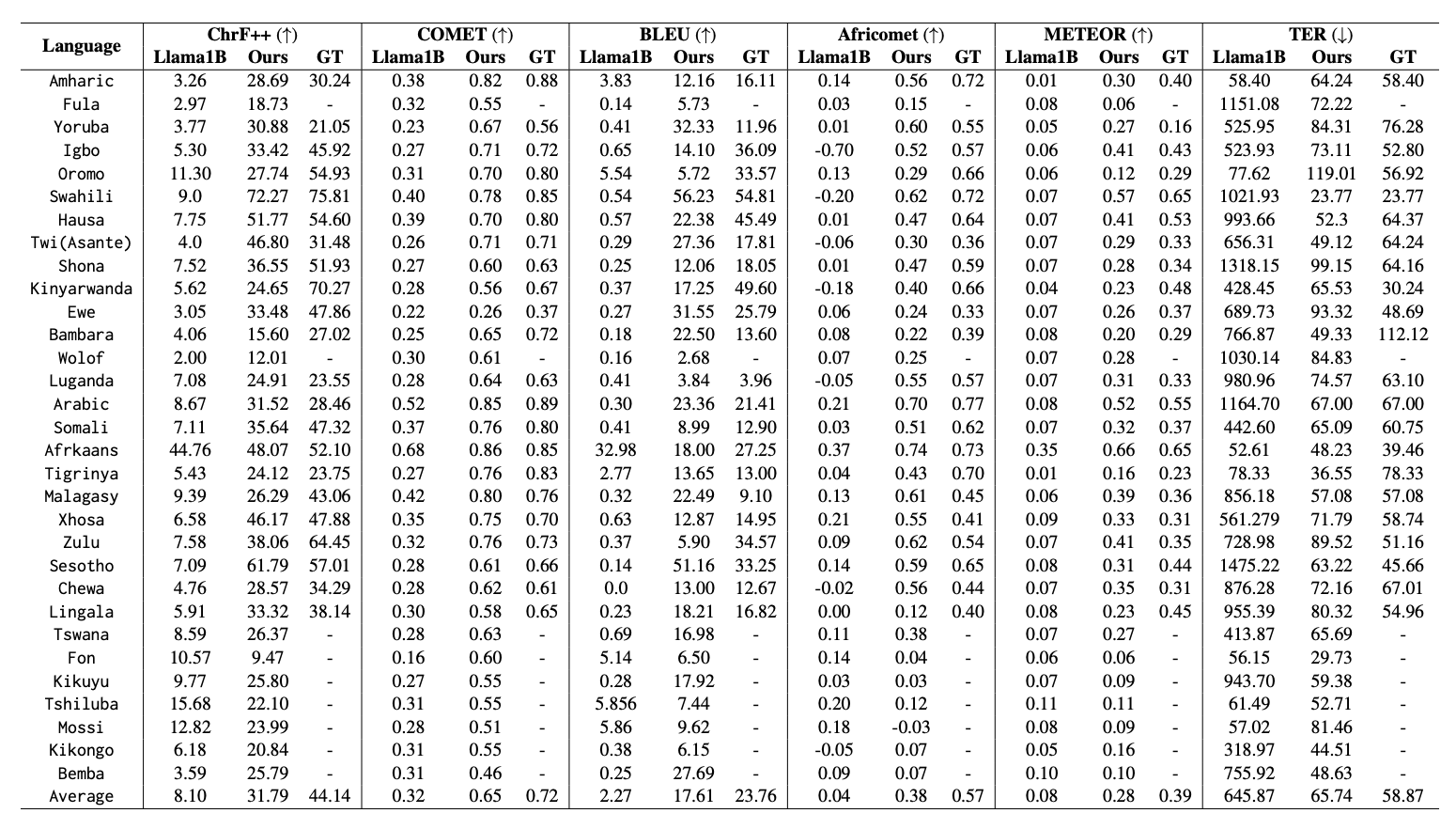
기계 번역의 품질을 평가하는 방법에는 여러 가지 있는데 그중 가장 널리 쓰이는 방법이 BLEU 점수입니다. BLEU 점수는 비교적 쉽게 계산할 수 있다는 장점이 있지만, 반면 기계 번역과 비교하기 위해 정답으로 사용할 번역문들이 필요합니다. 사람이 번역해도 한 문장에 서로 다른 여러 번역이 있을 수 있고, 정답 번역문과 기계 번역문에서 겹치는 단어를 세는 방식이기 때문에 기계 번역문에서 의미가 유사하지만 다른 단어를 사용하였을 경우 점수가 낮게 나오는 한계가 있습니다.
COMET3)은 이를 보완한 방법으로 많은 병렬 말뭉치를 학습해 모델을 만들었습니다. 이 모델을 통해 점수를 계산하기 때문에 정답 번역문이 없어도 되고, 그 결과 BLEU 점수보다 객관적으로 평가할 수 있다는 장점이 있습니다. 또, 단어 사이의 유사도를 계산하기 때문에 거의 같은 의미이지만 다른 단어를 썼어도 번역문 품질 측정에 반영이 됩니다.
하지만 아프리카 소수 언어는 COMET 점수 평가 모델에 학습 데이터가 거의 포함되어 있지 않아 점수 계산이 불가능합니다. 이를 위해 아프리카 소수 언어들로 COMET 점수 평가 모델을 학습함으로써 새로운 AfriCOMET4)을 만들어 좀 더 정확한 평가가 가능하도록 하였습니다.
|
|
|
정리
지난번에는 표준 문어체가 아닌 이집트 구어체, 사우디아라비아 구어체, 아랍에미리트 구어체 등 아랍 지역의 방언을 중심으로 기계 번역기 및 LLM을 학습시키는 방법을 살펴보았습니다. 아프리카나 인도에도 수많은 소수 언어가 존재하지만, 대부분은 아직 AI가 충분히 학습하지 못한 상황입니다. 세계에서 언어의 개수가 가장 많은 파푸아뉴기니 역시 비슷한 상황이며 시간이 갈수록 화자가 줄어들면서 소멸하는 언어도 늘어나고 있습니다.
플리토는 아랍어 방언부터 시작해서 다양한 소수 언어들을 수집 및 정제해 AI가 학습할 수 있도록 데이터셋을 만들고 있습니다. 텍스트뿐만 아니라 멀티모달 학습을 위해 이미지와 음성도 수집하고 있는 만큼 AI 시대에 어떤 언어도 소외되지 않도록 더 노력하겠습니다. 이러한 언어의 데이터셋이 필요하다면 언제든 플리토가 함께하겠습니다.
|
|
|
메타가 초지능(superintelligence) 개발 가속화를 위해 오픈소스 대신 폐쇄형 모델 전략으로 전환하고, 차세대 프로젝트 아보카도를 추진 중입니다. 새 모델은 내년 1분기 출시를 목표로 성능 테스트가 진행 중이며, 메타는 일정 지연 우려를 부인했는데요. 오픈소스 지향이던 메타의 방향 전환에는 스케일AI 창립자 출신 최고AI책임자 알렉산더 왕의 영향이 큰 것으로 알려졌습니다. 마크 저커버그는 과거 오픈소스 전략을 옹호했지만, 라마4의 부진 이후 폐쇄형 모델 병행 방침으로 전환했습니다. 메타는 아보카도 개발 과정에서 구글, 오픈AI, 알리바바 등 타사의 개방형 모델을 활용해 훈련 증류를 진행하고 있습니다.
👉🏻"AI, 나이 많고 피부 까무잡잡한 남자 사진 읽을 때 특히 오류 많아"
소니AI 연구팀은 전 세계 최초로 참여자의 동의를 받은 얼굴·전신 이미지로 구성된 윤리적 데이터 세트 피비(FHIBE)를 구축했습니다. 피비는 AI 학습용이 아닌 기존 AI의 공정성을 평가하기 위한 데이터 세트로, 네이처가 이를 커버스토리로 다루기도 했는데요. 해당 데이터 세트는 81개국 1981명의 이미지 1만여 장으로 이뤄졌으며, 모든 사진은 인권·개인정보 보호 절차를 거쳐 정제됐습니다. 피비로 CLIP, BLIP2 등 주요 AI를 평가한 결과, 젊은·밝은 피부·아시아계 인물에 대한 인식 정확도가 가장 높았으며, 반대로 고령층·어두운 피부·플러스 사이즈·장애인·종교 복장 착용자에 대한 인식 정확도는 크게 낮은 것으로 밝혀졌습니다. 연구팀은 이런 편향이 기존 학습 데이터의 불균형에서 비롯된 것이라고 설명했습니다.
👉🏻'30년 검색 노하우'로 AI모델 한계 넘은 구글
구글의 제미나이3 프로가 AI 성능 벤치마크 인류의 마지막 시험에서 GPT-5.1을 제치며 오픈AI를 앞질렀습니다. 제미나이3 프로는 37.5%의 정답률을 기록하며 GPT-5.1의 26.5%보다 크게 높았는데요. 핵심 성능 비결은 시연 기반 검색증강생성(DRAG) 기술과 이를 발전시킨 반복 시연 기반 IterDRAG 기술 덕분으로, 두 기술은 검색 정확도와 추론력을 향상시켰습니다. 구글의 지식그래프는 단어 간 관계를 반영해 맥락을 이해하도록 돕고, DRAG 학습에 접목돼 AI의 환각 발생을 줄였습니다. 구글은 검색 색인, 유튜브, 지도, 크롬 등 자사 플랫폼에서 얻은 멀티모달 데이터를 AI 학습에 활용해 경쟁사 대비 자료 폭과 다양성을 확보했습니다.
|
|
|
플리토가 '제62회 무역의 날' 기념식에서 '700만불 수출의 탑'을 수상했습니다. 지난해 500만불 수출의 탑에 이어 두 번째 수상으로, 플리토는 글로벌 AI 시장에서 지속적인 성장세를 입증했습니다. 이번 성과는 고품질 AI 학습용 데이터를 공급하는 데이터 사업 부문과, 해외 행사와 글로벌 인프라에 도입된 AI 통번역 솔루션의 성과가 주요하게 작용했는데요. 특히 '라이브 트랜스레이션'은 구글, 메타, AWS 등 200여 개 행사에서 활용되었으며, '챗 트랜스레이션 엔터프라이즈'는 서울역과 인천공항 등에 도입되어 글로벌 소통을 지원하고 있습니다. 플리토는 언어 데이터 기반 기술 경쟁력을 토대로 안정적인 수출 성장을 이어가고 있으며, 이번 수상을 계기로 글로벌 시장에서의 입지를 더욱 강화할 계획입니다. |
|
|
이정수 플리토 대표가 아주경제 인터뷰를 통해 전 세계 어디서든 구글 앱처럼 쓰이는 보편적 언어 플랫폼을 만들겠다며 B2C 확장에 대한 포부를 밝혔습니다. 플리토는 언어 데이터 기반 AI 기업으로, 전체 매출의 90%가 데이터 사업에서 발생한다고 밝혔는데요. 최근 출시한 초개인화 AI 통번역 앱인 '챗 트랜스레이션(Chat Translation)'을 언급하며 사용자의 데이터를 학습해 개인만의 번역 엔진을 제공하는 초개인화 솔루션이라고 설명했습니다. 또한, 플리토는 중동 시장, 특히 아랍어 데이터 부족 문제를 새로운 기회로 보고 현지 파트너십 강화와 아랍어 AI 개발에 집중하고 있으며, 국가대표 AI 모델 개발에도 업스테이지와의 협력을 통해 전력을 다하고 있다고 밝혔습니다. 이정수 대표는 "AI는 버블이 아니라 저평가 상태"라며 데이터 자산의 가치를 강조했습니다.
|
|
|
Beyond Language Barriers!
|
|
|
플리토 (Fliitto Inc.)
서울 강남구 영동대로96길 20 대화빌딩 6층
|
|
|
|
|