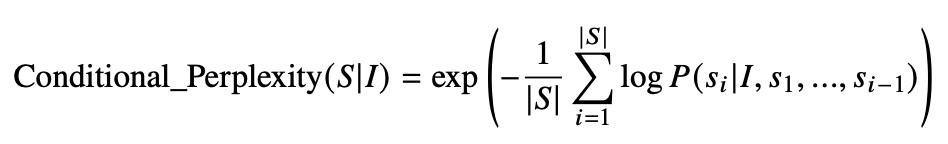2025년 12월 5주차 - AI Data News Lab 2025년 12월 5주차 AI Data News Lab |
|
|
|
프롬프트 한 줄이면 '30초 엘사'가 뚝딱❄️ |
|
|
월트디즈니가 오픈AI와 10억 달러 규모 지분 투자를 하고 자사 캐릭터를 오픈AI의 동영상 플랫폼 '소라'에 제공할 것이라고 밝혔습니다. 이번 협약을 통해 디즈니는 겨울왕국, 주토피아, 스타워즈, 마블 시리즈 등 자사 캐릭터를 오픈AI의 소라에 제공함으로써 이용자들은 디즈니 캐릭터를 활용해 직접 단편 영상을 제작할 수 있습니다.
이번 계약은 할리우드 메이저 스튜디오와 AI 기업 사이의 협업 중 최대 규모로 평가받고 있습니다. 소라 이용자들은 3년 동안 캡틴 아메리카, 엘사, 미키 마우스 등 다양한 캐릭터로 팬 콘텐츠를 제작할 수 있으며, 이 중 일부는 디즈니플러스를 통해 공개될 예정입니다.
|
|
|
출처: [The Batch] Disney Teams Up With OpenAI |
|
|
디즈니는 이와 동시에 명확한 제한선도 제시했습니다. 배우의 얼굴과 목소리 사용은 금지되며, 디즈니 IP를 AI 학습 데이터로 활용하는 것도 허용되지 않은 건데요. 이러한 제한은 캐릭터 중심의 영상 제작은 허용하되 초상권과 음성 권리를 보호하기 위한 조치로서, 생성형 AI 확산 속에서 권리 침해와 노동 이슈를 최소화하려는 의도인 것으로 파악됩니다.
AI 물결 속에서 경쟁 스튜디오들이 여전히 신중한 태도를 보이는 가운데 디즈니는 가장 빠르게 AI 기업과의 협업을 선택했습니다. 이번 계약은 디즈니가 AI를 콘텐츠 제작의 대체 수단이 아닌, IP 소비 확장을 위한 또 다른 장치로 활용하고 있음을 보여줍니다.
|
|
|
AI가 인도어 스펙트럼을 전반적으로 아우르며 추론할 수 있을까?
인도는 언어적 다양성이 놀라울 정도로 방대한 국가입니다. 공용어만 22개, 방언은 수백 개에 이르며, 매일 10억 건이 넘는 대화가 지역, 맥락, 문화에 따라 형성되고 있습니다. 전문가들은 이렇게 다양한 시장을 지원하려면, AI 시스템이 여러 언어와 문화 간 원활히 작동해야 한다고 하는데요.
이러한 배경에서 탄생한 것이 바로 오픈AI의 IndQA입니다. IndQA는 인도 언어 및 문화적 맥락 전반에서 AI 모델의 추론 능력을 평가하기 위해 설계된 새로운 벤치마크(Benchmark)입니다.
|
|
|
출처: [IBM Think] Can your AI reason across the Indic language spectrum? |
|
|
IndQA는 앞서 말했듯이 10개 도메인과 12개 언어를 포괄하여, AI 시스템이 현실의 인도를 이해하도록 이끌고 있습니다. 따라서, '타밀어 속담을 해석할 수 있을까?', '힌디어 문학적 상황을 논리적으로 풀어낼 수 있을까?', '벵골어 뉴스 기사 속 미묘한 뉘앙스를 이해할 수 있을까?'와 같은 질문을 던지며 AI가 인도를 복합적으로 받아들이는 평가 기준을 제시합니다.
인도에서 AI 솔루션을 구축하는 개발자와 기술 리더에게 IndQA는 단순 번역을 넘어 현지화로의 전환을 의미합니다. 단지 인도 언어를 말하게 만드는 것이 아닌, 그 언어로 생각하게 만드는 것이 목표인 겁니다. 인도 산업 전반에서 AI 도입이 가속화되는 가운데, 특히 지역적 맥락에서 실전 적합성을 측정하는 도구의 중요성은 더욱 커지고 있는데요.
IBM 방갈로어 이노베이션 엔게이지먼트 엑셀러레이션 리더 재스비르 카우르(Jasbir Kaur)는 인도에서 비즈니스를 운영하는 기업에게 "언어적 정확성은 있으면 좋은 것(nice-to-have)이 아니라 반드시 필요한(mission-critical) 요소며, 이러한 벤치마크는 AI 솔루션이 단순히 기능적으로 작동하는 수준을 넘어, 문화적, 맥락적으로도 지능적으로 작동한다는 신뢰를 제공한다"고 설명했습니다.
IndQA는 독립적으로 만들어진 프로젝트가 아닌, 인도 연구자, 언어학자, 도메인 전문가 등이 참여해 문제를 설계하고, 결과를 검토하며, 문화적 정합성을 확보했습니다. 이를 통해 각 질문마다 채점 기준, 이상적인 답변, 그리고 정확성을 위한 영어 번역이 함께 정의되었습니다. 모든 프롬프트는 동료 검토와 여러 차례의 수정 과정을 거쳐 최종 확정되었으며, 이로써 IndQA는 단순한 벤치마크가 아니라 문화적으로 정합한 AI 평가를 위한 엄격하게 구축된 표준으로 자리 잡았습니다.
|
|
|
사람과 LLM은 텍스트 요약을 어떤 기준으로 평가할까?
기계 번역의 역사는 매우 오래되었습니다. 1950년대 미국에서 규칙 기반 영어–러시아어 기계 번역기가 개발된 이후, 기계 번역 기술은 지속적으로 발전해 왔습니다. 이러한 기술 발전과 함께 기계 번역 성능을 정량적으로 평가하기 위한 지표도 등장했으며, 그중 대표적인 지표가 BLEU1)입니다.
BLEU는 기계 번역 결과와 사람이 번역한 정답 문장 사이에서 일치하는 단어의 비율을 기준으로 점수를 산출하는 방식입니다. 이로 인해 의미는 동일하지만 표현 방식이 다른 경우에는 점수가 낮게 산출되는 구조적 한계를 지니고 있습니다. 텍스트 요약의 품질을 평가할 때는 ROGUE2) 지표가 널리 사용되고 있습니다. 그러나 ROUGE 역시 BLEU와 마찬가지로 단어 단위로 일치 여부를 판단하기 때문에 요약문의 의미적 충실도나 전반적인 품질을 측정하는 데에는 한계가 있습니다.
최근에는 대규모 언어 모델(LLM)의 성능이 크게 향상되면서 번역이나 요약뿐만 아니라 다양한 자연어 처리 과제를 평가할 때도 LLM이 활용되고 있습니다. 이른바 LLM-as-a-Judge 방식은 다수의 연구에서 모델 성능을 평가하는 주요 방법 중 하나로 자리 잡았습니다. 다만 이러한 방식은 LLM이 어떤 기준이나 특징에 근거해 평가 판단을 내렸는지에 대한 설명 가능성이 제한적이라는 점에서, 평가 결과의 해석과 신뢰성 측면에서 여전히 해결해야 할 과제를 안고 있습니다.
요약 평가 기준 찾아보기
Exploring the features used for summary evaluation by Human and GPT3)에서는 사람과 GPT가 텍스트 요약의 품질을 평가할때 실제로 어떤 기준이나 특징이 작용하는지 살펴보고 있습니다. 이를 위해 AI가 요약을 얼마나 잘 하였는지를 평가하기 위해 구축된 데이터셋인 SummEval4)을 벤치마크로 활용하였습니다.
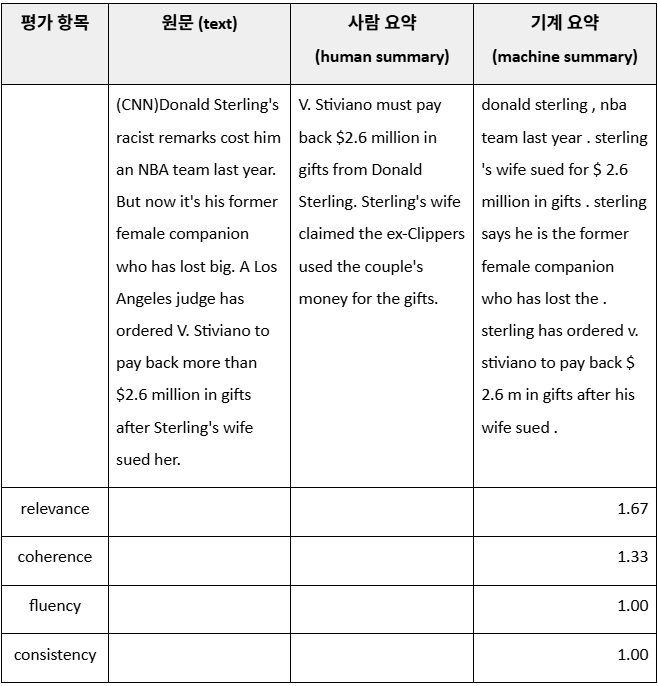
SummEval 벤치마크 데이터셋 예시
|
|
|
SummEval은 원본 텍스트를 바탕으로 AI가 생성한 요약 결과(machine summary)를 네 가지 평가 기준에 따라 사람이 직접 품질을 평가한 데이터셋입니다. 단일 평가자의 판단에는 오류나 편향이 발생할 수 있기 때문에 동일한 가이드라인을 기반으로 여러 평가자가 요약을 평가하도록 하였으며 그 결과를 평균해서 최종 점수를 산출하였습니다.
항목별 평가 결과와 상관관계 파악하기
GPT와 같은 대규모 언어 모델에게 요약 결과에 대한 평가를 요청하는 경우, 단순한 점수뿐만 아니라 평가에 대한 상세한 설명까지 함께 확인할 수 있습니다. 그러나 생성형 AI의 기본 구조인 트랜스포머(Transformer)의 특성상 이러한 응답은 사람처럼 의미를 이해해서 답변했다기 보다는 확률에 기반해 단어를 선택하고 문장을 생성하였기 때문에 그 설명이 어떤 근거와 판단 기준에 기반하고 있는지를 명확히 파악하기에는 한계가 존재합니다.
본 논문에서는 SummEval 벤치마크 데이터셋을 기반으로 원문과 요약문에 대해 사람이 부여한 평가 점수와 LLM이 평가한 결과를 다양한 평가 지표를 활용해 수치화하였습니다. 이후 각 평가 지표의 값과 사람 평가 점수 사이의 상관관계를 분석함으로써, 요약 품질 평가에 영향을 미치는 핵심 요인이 무엇인지를 체계적으로 규명하였습니다.
분석에 활용된 지표로는 조건부 퍼플렉시티(Conditional Perplexity), 엔트로피 요약(Entropy Summary), 퍼플렉시티 요약(Perplexity Summary), 지니 요약(Gini Summary) 등 정보 이론에 기반한 지표들이 포함되었습니다. 여기에 더해 어려운 단어 수, 음절 수, 문장 길이 등 텍스트의 구조적 복잡도를 측정하기 위한 Flesch Reading Ease, ARI, SMOG 등과 같은 가독성 지표가 함께 사용되었습니다.
|
|
|
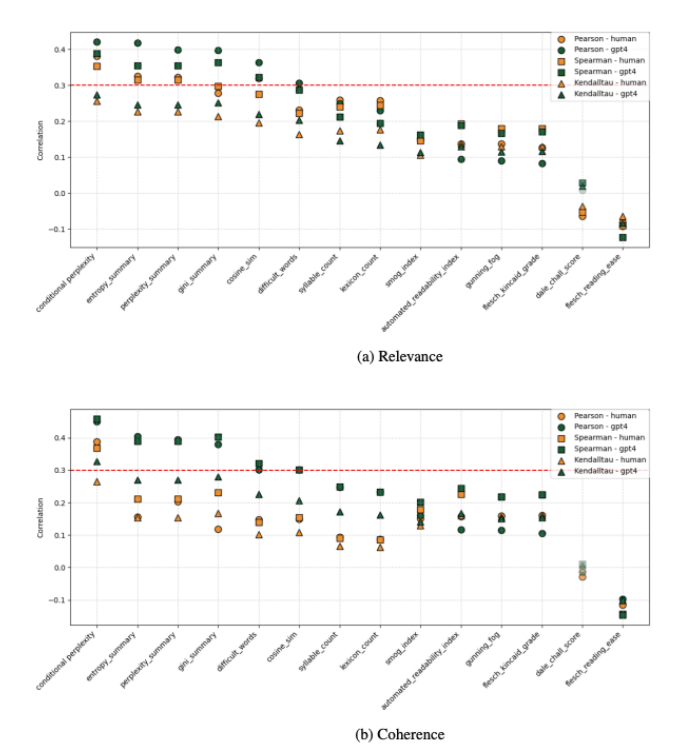
< 그림 1. 각 평가 지표와 사람 / GPT 평가 점수와의 상관관계 >
|
|
|
그 결과 위 그래프에서 알 수 있는 것처럼 전반적으로 정보 이론 기반 지표들이 높은 상관관계를 보였으며, 그중에서도 특히 조건부 퍼플렉시티가 사람 평가와 가장 높은 상관관계를 나타내었다는 점을 확인할 수 있습니다. 조건부 퍼플렉시티를 간단히 설명하면 원문(I)이 주어졌을 때 요약문(S)의 단어들이 얼마나 예측 가능한지 측정하는 지표입니다. |
|
|
상관관계 검증하기
분석 결과 평가 점수와 조건부 퍼플렉시티 간의 상관관계가 가장 높게 나타났습니다. 그러나 반대로 조건부 퍼플렉시티의 값이 크거나 작아졌을 때 그 변화에 따라 GPT의 평가가 사람의 평가에 더 가까워지는지 또는 오히려 멀어지는지에 대해서는 기존 실험만으로는 확인하기 어려웠습니다.
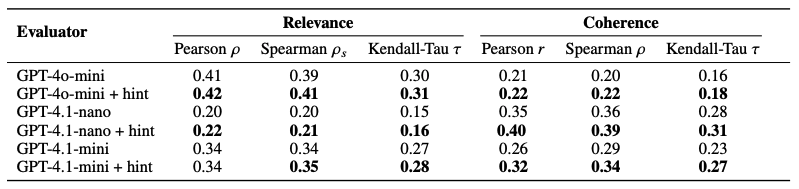
이를 검증하기 위해 GPT 평가 프롬프트에 조건부 퍼플렉시티를 힌트로 명시하고, 이를 참고하여 요약을 평가하도록 하는 실험을 추가로 진행하였습니다. 그 결과 힌트를 제공하지 않았을 때보다 GPT의 평가가 사람의 평가 결과와 더욱 유사해짐을 알 수 있습니다. 이는 LLM이 평가를 수행할 때 사람이 내린 판단과 가장 가까운 결과를 얻기 위해서는 기존 프롬프트에 더해 평가에 영향을 미치는 핵심 지표들을 힌트로 포함하는 것이 필요하다는 것을 보여주고 있습니다.
- 힌트 예시: These metrics are important for evaluation: - for summary: entropy, perplexity, Gini index, syllable count, lexicon count, difficult words - cosine similarity between source and summary
|
|
|
< 표 1. 힌트를 추가하였을 때 관련성과 일관성 변화 > |
|
|
정리
대규모 언어 모델(LLM)의 성능이 지속적으로 향상됨에 따라, 앞으로 더 많은 분야에서 객관성과 효율성을 확보하기 위한 방법으로 사람을 대신해 LLM이 평가를 수행하는 LLM-as-a-Judge 방식이 널리 활용될 것으로 예상됩니다.
그러나 지금까지는 LLM이 왜 특정한 평가 판단을 내린 이유에 대해, 모델이 생성한 설명을 제외하면 그 기술적인 판단 근거를 명확히 파악하기 어려운 한계가 존재했습니다. 본 논문에서는 ‘요약’이라는 태스크를 대상으로 다양한 지표와 평가 결과 사이의 상관관계를 분석함으로써 LLM의 평가 판단이 어떤 기술적 특징에 기반하고 있는지를 보다 구체적으로 확인하였습니다.
플리토는 LLM 학습을 위한 데이터셋 구축뿐만 아니라, 다양한 평가 목적에 사용할 수 있는 벤치마크 데이터셋도 함께 구축하고 있습니다. 한국어를 비롯해 각 언어의 고유한 특성과 사용 맥락을 충실히 반영해, 요약뿐만 아니라 번역, 문체 변환 등 다양한 자연어 처리 태스크를 정밀하게 평가할 수 있는 데이터셋을 구축하고 있으며, 이를 필요로 하는 기업과 기관에 제공해 나갈 계획입니다.
|
|
|
생성형 AI 영상, 이미지 시장이 구글, 오픈AI, 메타의 3강 구도로 재편되고 있습니다. 메타는 차세대 생성 AI 모델 망고(Mango)를 2026년 상반기 공개할 예정이며, 동시에 코딩 특화 대규모 언어모델 아보카도(Avocado)를 선보여, 자사 플랫폼 전반의 개인화 콘텐츠를 강화할 계획입니다. 오픈AI는 소라2를 통해 고품질 영상 생성 시장을 선점하고, 디즈니 및 어도비와의 제휴로 콘텐츠 생태계를 확장했습니다. 이를 통해 소라와 챗GPT에서 마블, 스타워즈 등 디즈니 IP 기반 영상 이미지를 제작할 수 있게 됐습니다. 구글은 제미나이 3.0의 이미지 생성 및 편집 기능 나노 바나나(Nano Banana)를 출시하며 오픈AI와 메타를 견제하고 있습니다.
👉🏻챗GPT 대화 뒤 미성년자 '극단적 선택'…오픈 AI, 나이 판별 도입
최근 청소년들이 챗GPT와 대화한 뒤 극단적 선택을 하는 사건이 잇따르자, 오픈AI가 이용자 연령을 판별하는 AI 모델을 도입했습니다. 새 모델은 이용자의 대화 주제, 사용 시간대 등 다양한 신호를 분석해 18세 미만 여부를 예측합니다. 미성년자로 판별되면 챗GPT는 폭력, 성적, 위험 행동 묘사 등을 차단하고, 위기 상황에서는 긴급 서비스 연결을 권고합니다. 해당 18세 미만 환경은 미국심리학회(APA) 자문을 거쳐 마련됐으며, 성인을 오인할 경우 신분증이나 셀카 영상으로 인증이 가능합니다.
👉🏻30일 코엑스서 '국가대표 AI' 1차 평가전…시민 체험도
과학기술정보통신부는 독자 AI 파운데이션 모델 프로젝트 1차 발표회를 이번 달 30일 서울 코엑스에서 개최합니다. 해당 행사는 네이버클라우드, 업스테이지, SK텔레콤, NC AI, LG경영개발원 AI연구원 컨소시엄 등 5개 참가팀이 개발한 AI 모델을 공개하는 자리인데요. 각 팀은 20분씩 모델의 성능과 특징을 시연하며, 행사장 로비에서는 시민들이 직접 체험할 수 있는 AI 부스도 운영합니다. 과기정통부는 참가팀 모델 성능이 글로벌 최고 수준의 96% 이상에 도달하도록 지원할 계획입니다. 1차 평가 결과는 내년 1월 15일 이전 발표되며, 5팀 중 한 팀이 탈락해 최종 1~2팀이 남을 때까지 6개월 단위 경쟁이 이어집니다.
|
|
|
플리토가 과학기술정보통신부와 한국데이터산업진흥원이 주관한 '2025 데이터 품질대상'에서 '한국데이터산업진흥원장상'을 수상했습니다. 이번 수상은 플리토가 구축한 한국어 논리추론(CoT) 데이터셋이 우수한 품질 관리 체계와 운영 모델로 인정받은 결과인데요. 플리토의 CoT 데이터는 한국어 언어 구조와 사고 전개 특성에 최적화되어 영어권 중심 CoT 데이터의 한계를 보완했다는 점에서 높은 평가를 받았습니다. 또한 플리토는 업스테이지 컨소시엄의 독자 AI 파운데이션 모델 프로젝트에서 한국어 추론 데이터 품질과 구조를 총괄하는 핵심 파트너로 참여 중입니다. 김진구 플리토 CDO는 "이번 수상이 자사의 데이터 기술력과 관리 체계가 공인된 사례"라며, 한국형 데이터 품질 기준 확산과 글로벌 AI 생태계 기여를 약속했습니다.
|
|
|
플리토가 과학기술정보통신부가 주관하는 'AI·디지털 비즈니스 파트너십 특화 프로그램(AIIA)'을 통해 미국 동부 시장 진출 기반을 강화했습니다. 플리토는 뉴욕대(NYU) 스턴 비즈니스 스쿨의 액셀러레이터 프로그램과 연계해 미국 내 글로벌 파트너십 발굴 및 세일즈 전략 고도화에 주력했는데요. 그 결과, 통번역 솔루션 사업의 글로벌 고객 수가 전년 대비 400%, 수출 매출이 245% 증가하며 가시적 성과를 거뒀습니다. 플리토는 현지 시장 인사이트를 반영해 B2C 실시간 통번역 솔루션 챗 트랜스레이션도 새롭게 출시했습니다. 또한 스턴 시그니처 프로젝트를 공동 수행하며 미국 언어 서비스 시장 분석 및 전략 설계를 위한 연구를 진행 중입니다. 플리토는 이번 성과를 바탕으로 미국뿐 아니라 언어 취약 지역으로 PoC와 파트너십을 확장해 글로벌 시장에서 입지를 공고히 할 계획입니다.
|
|
|
Beyond Language Barriers!
|
|
|
플리토 (Fliitto Inc.)
서울 강남구 영동대로96길 20 대화빌딩 6층
|
|
|
|
|